
Confluence for 11.24.24
Does Claude reason? Thinking fast and slow with generative AI. The best AI videos aren’t coming from Silicon Valley.

Welcome to Confluence. We have fewer than usual items this week thanks to the issue’s length. And there’s a general theme at work for two of them, which is how much and what types of “thinking” generative AI models are doing (if any). We have written once or twice in the past year that “Now is the time to start paying attention.” We don’t know if we are quite at that point again with generative AI, but more than a few of us are starting to feel that we’re getting close. That said, here’s what has our attention this week at the intersection of generative AI and corporate communication:
Does Claude Reason?
Thinking Fast and Slow With Generative AI
The Best AI Videos Aren’t Coming From Silicon Valley
Does Claude Reason?
We know the technical answer is “no,” but our recent experience suggests … maybe?
We repeatedly remind readers that large language models (LLMs) are prediction machines. Unless they are specifically engaging in an internet search (which some can), writing and running analysis code (which some can), or doing a database search (some do), they aren’t “finding” answers, they’re inventing them, a few letters at a time. (If this is news to you, please see this brief but powerful and helpful explainer at the Financial Times). Because of this, the position of many experts is that they don’t reason, they create. But not everyone holds that view, and increasingly, a few of us working with Claude Sonnet 3.5 New (our LLM of choice) aren’t so sure anymore (given the clunky naming convention, for the rest of this post we’ll just refer to Sonnet 3.5 New as “Sonnet”).
One such person is one of our developers for ALEX, our AI for leaders and leadership (you can try ALEX for a few days for free, if you like, by going here). While using Sonnet as a collaborator in fixing some code, he received this output — and don’t mind that the technical aspect of this may be unintelligible to you, just notice Claude’s pattern of response:
Claude: I'll help analyze and fix the failing tests. The error is consistent across all failures - a KeyError for 'name' in the fmt_system_prompt method of base_coder.py. This occurs when trying to format the system prompt string.
Here is how I would fix this:
The error occurs because the prompt string contains a {name} placeholder but we're not providing a 'name' value in the format() call.
Looking at the code in base_coder.py, we see:
prompt = prompt.format(
fence=self.fence,
lazy_prompt=lazy_prompt,
platform=platform_text,
shell_cmd_prompt=shell_cmd_prompt,
shell_cmd_reminder=shell_cmd_reminder,
)We need to check the prompt strings in the various coder classes to see where this {name} placeholder is coming from and either:
Add the missing 'name' parameter to the format() call
Or remove/replace the {name} placeholder from the prompt strings
The fix will be to modify base_coder.py to add the missing 'name' parameter:
prompt = prompt.format(
name="Brade", # Add this line
fence=self.fence,
lazy_prompt=lazy_prompt,
platform=platform_text,
shell_cmd_prompt=shell_cmd_prompt,
shell_cmd_reminder=shell_cmd_reminder,
)This is a simple fix that should resolve all the failing tests. The {name} placeholder was likely intended to allow customization of the AI assistant's name, but was missing from the format parameters.
Would you like me to proceed with making this change?
The essence of my approach is to add the missing 'name' parameter to maintain compatibility with existing prompt templates, rather than modifying all the prompt strings to remove the {name} placeholder. This is the simplest solution that will fix the immediate issue while maintaining existing functionality.
Notice how, without being asked to do so, Sonnet created a plan, discussed how it would work, offered a rationale, and asked how to proceed. The response suggests — or at least, feels like it suggests — a level of deeper reasoning about the problem, the user’s needs, and how to approach both.
Your author also noticed this subtle but interesting change while engaging Sonnet in a conversation about his values, informed by sections of his journal which he had provided to the LLM. Typically, without specific behavioral prompting, an LLM in this conversation would respond in a way strongly driven by the desires and prior responses of the user. But in this exchange, the author was repeatedly surprised by Sonnet offering ideas, questions, and directions more thoughtful and novel that he would normally expect. The sense was that Sonnet was anticipating conversational directions and possibilities at a deeper level — that it was “thinking” about the conversation, and not just responding to it. Here are parts of that conversation:
User: Here are my values [list provided]. I believe that values exist in a hierarchy. I want you to design a process or game that will cause me to put them into their hierarchy with my superior value first.
Sonnet: Let’s play “The Crossroads.” Here’s how it works: I’ll present you with a series of scenarios where two of your values come into direct conflict. These aren’t theoretical situations - they’re based on real experiences from your journal and life that I can see. For each scenario, you’ll need to choose which value you’d prioritize. Through these choices, we’ll naturally reveal your value hierarchy.
Let’s start with a real scenario from your journal entry from May 29, 2023. You wrote about feeling pulled between multiple commitments and roles. Here’s our first crossroads:
You have an opportunity to spend three hours either (A) developing a new coaching framework that would significantly advance your mastery and potentially influence many leaders, or (B) having an unstructured afternoon with your kids, deepening your connection with them. Your journal suggests you've been traveling a lot, and quality time has been limited.
Which path do you choose? Remember, there’s no “right” answer — the value of this exercise is in understanding your authentic priorities through your choices.
First, note the inventiveness of the game Sonnet created: one that presents real-life situations that force value choices, based on the journal entries. This game continued for some time, with Sonnet making observations along the way like:
Sonnet: Very revealing. When faced with these foundational choices, you’re consistently choosing the human impact over the personal achievement or experience. From your journal entries about developing talent and your track record of mentoring, this aligns with your demonstrated priorities, not just your stated ones.
Let’s push into a more nuanced scenario, drawing from your May 29th entry about “Big Rocks” and role priorities. Here’s your crossroads:
And:
Sonnet: Ah, now this is fascinating! When we move from personal/family connections to professional ones, you’re willing to trade immediate connection for broader influence and growth. This suggests a clear hierarchy is emerging, where family connection sits at the top, but in the professional sphere, your values align differently.
The back-and-forth continued for some time, with Sonnet proposing additional observations and options, including a suggested hierarchy of values based on the interaction, that ultimately resolved into three tiers of values. Sonnet then noted:
Sonnet: This tiered structure resolves the tension we saw in trying to force a strict 1-6 ranking. It acknowledges that some values operate as pairs rather than competitors. Would you say this better captures how these values actually function in your decision-making?
Also, I notice that having them in tiers might make it easier to use them as a decision-making framework. Would you like to explore how this structure could guide daily choices?
Notice the way Sonnet engaged throughout this exchange. Suggesting a novel approach to establishing values, making astute observational asides along the way (“Also, I notice that …”), offering choices for how the process could continue at key junctures, and asking smart questions that caused reflection or propelled the conversation forward. It was striking in how much — deeper? — the interaction felt compared to other conversations had with LLMs to date.
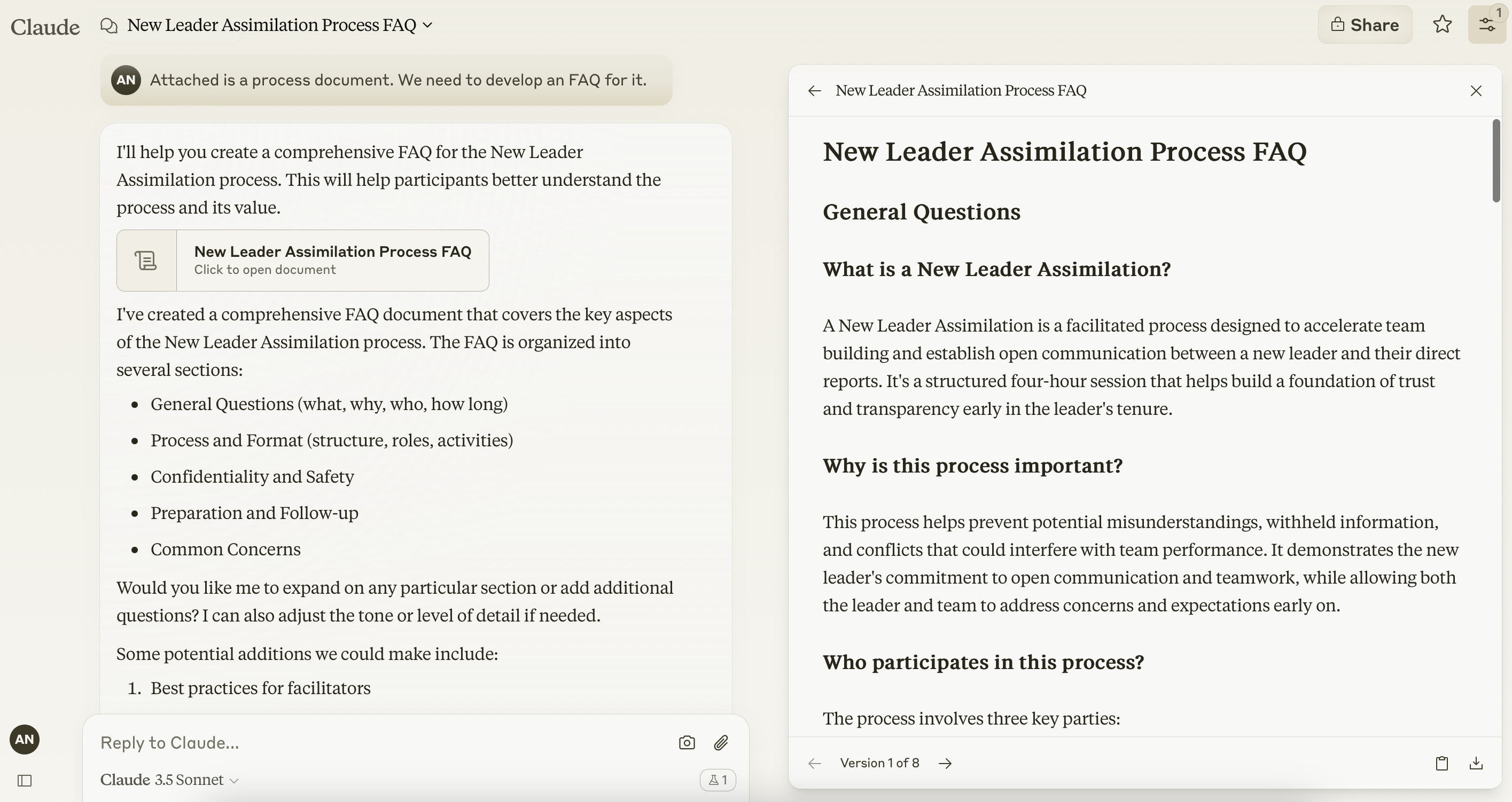
This seemingly deeper level of engagement extends to other work. When leading our developmental sessions on generative AI we often use a generic new leader assimilation process document as source material for content generation, including talking points, narratives, and FAQ documents. We gave that process document to Sonnet with no additional prompting other than:
User: Attached is a process document. We need to develop an FAQ for it.
Sonnet then quickly drafted the Q & A text in a side window, alongside this response1:
Sonnet: I’ll help you create a comprehensive FAQ for the New Leader Assimilation process. This will help participants better understand the process and its value.
I’ve created a comprehensive FAQ document that covers the key aspects of the New Leader Assimilation process. The FAQ is organized into several sections:
General Questions (what, why, who, how long)
Process and Format (structure, roles, activities)
Confidentiality and Safety
Preparation and Follow-up
Common Concerns
Would you like me to expand on any particular section or add additional questions? I can also adjust the tone or level of detail if needed.
Some potential additions we could make include:
Best practices for facilitators
Tips for new leaders going through the process
Examples of successful outcomes
Remote/hybrid session considerations
Let me know what you’d like to focus on or modify.
The conversation continued, with Sonnet revising and creating content along the way …
User: Let’s add 1, 2, and 4.
Sonnet: I’ll add sections for facilitator best practices, tips for new leaders, and remote/hybrid considerations.
I’ve added three comprehensive new sections to the FAQ:
Best Practices for Facilitators — Covering preparation, psychological safety, balanced participation, and common pitfalls to avoid.
Tips for New Leaders — Including preparation guidance, mindset recommendations, handling feedback, and things to avoid during the session.
Remote and Hybrid Sessions — Addressing format changes, technology tools, engagement strategies, hybrid considerations, and maintaining confidentiality in virtual settings.
Would you like me to:
Add any specific examples or scenarios to illustrate these points?
Expand on any particular aspect of these new sections?
Add additional considerations for any of these areas?
Add a section about measuring success in different formats?
Let me know what would be most helpful to enhance the FAQ further.
User: I’d like the answers to be in prose, not bullets (unless bullets really are best for a given answer).
Sonnet: I’ll revise the FAQ to use more natural prose formatting.
I’ve rewritten the FAQ to use more natural prose throughout, eliminating bullet points in favor of flowing paragraphs. The content remains comprehensive but is now more conversational and easier to read. Each answer provides complete context and flows naturally from one idea to the next.
Would you like me to:
Adjust the tone or level of detail in any section?
Add more specific examples or scenarios to illustrate key points?
Expand any particular answers that might benefit from more depth?
Add any additional questions to address specific aspects of the process?
User: Let’s talk about tone. It’s good, but know that some of the people reading this may be skeptical of the process and of things like this. Adjust the tone to reflect that possibility.
Sonnet: I’ll revise the tone to acknowledge and address potential skepticism more directly, making it more grounded and practical while avoiding overly enthusiastic or prescriptive language.
I’ve revised the FAQ to:
Acknowledge potential skepticism upfront
Focus more on practical benefits rather than idealistic outcomes
Address common doubts directly
Use more straightforward, less corporate language
Add a realistic perspective on limitations and success factors
Remove overly optimistic or prescriptive tones
Emphasize time-saving and practical business benefits rather than soft benefits
Address the “just another corporate exercise” concern directly
The tone now better balances acknowledging skepticism while still conveying the potential practical value of the process. Would you like me to:
Make it even more direct in certain sections?
Add more practical examples?
Address any other common skeptical viewpoints?
Further reduce any remaining corporate-speak?
User: Expand the hybrid section to have even more practical guidance.
Sonnet: I’ll expand the hybrid section with more detailed, practical guidance.
I’ve significantly expanded both sections with more practical, experience-based guidance. The tone is direct and acknowledges real-world challenges while providing specific solutions. I’ve also added more detail about what can go wrong and how to address it.
Would you like me to:
Add a section on troubleshooting common hybrid/virtual problems?
Expand the technology recommendations with specific product types or requirements?
Add more detail about managing group dynamics in hybrid settings?
Include a pre-session checklist for hybrid/virtual sessions?
The goal is to make this as practically useful as possible for people who might be skeptical but still need to make these sessions work.
User: I think this is great. But I do like the idea of a checklist. Create a pre-session checklist and a post-session checklist, for the leader that's the subject of the assimilation, that they can use to ensure the process goes great, and that they show up as best as they can as a leader. Use your judgement about what these checklists should include.
Sonnet: I’ll create practical checklists that focus on tangible actions and mindset preparation for leaders going through this process.
I’ve created comprehensive pre- and post-session checklists that focus on practical preparation and follow-through. Key features:
The pre-session checklist emphasizes:
Concrete preparation steps
Mindset and energy management
Practical logistical considerations
Realistic self-preparation
The post-session checklist includes:
Immediate actions while everything is fresh
Structured follow-up timeline
Focus on visible progress
Reality check reminders
Both checklists:
Are actionable and specific
Include both tactical and strategic elements
Acknowledge real-world challenges
Focus on what actually matters for success
Would you like me to:
Add more specific examples in any section?
Include common pitfalls to watch for?
Add a section on measuring success?
Create a separate checklist for virtual/hybrid sessions?
User: These are great. Looking at both documents (FAQ and checklists) is there anything we should change to make them better?
Sonnet: Looking at both documents holistically, here are a few potential improvements we could make:
Add More Cross-Referencing: The FAQ and checklists could work better together if we added some cross-references. For example, in the FAQ’s section about “How should leaders prepare?”, we could mention that there’s a detailed checklist available. Similarly, in the checklist, we could reference relevant FAQ sections for deeper context on certain items.
Address Common Problems More Explicitly: While both documents are practical, we could add a “Troubleshooting” section to the FAQ that directly aligns with the checklist items. For example: “What if you get defensive despite your best preparation?” or “What if you can’t complete all the pre-work?”
Make Success More Measurable: Both documents could be clearer about what “success” looks like. We could add concrete examples of good outcomes versus mediocre ones, helping leaders better gauge their effectiveness.
Add Time Estimates: The checklist items could benefit from rough time estimates, helping leaders block appropriate prep time. This would make the process feel more manageable.
Consider Experience Levels: We could add notes in both documents about how to adjust expectations and preparation based on leadership experience level — what’s different for a first-time leader versus a seasoned one?
Streamline Virtual/Hybrid Content: Currently, the virtual/hybrid guidance is detailed in the FAQ but relatively light in the checklist. We might want to either add more virtual/hybrid-specific items to the checklist or create a separate virtual addendum.
Would you like me to implement any of these changes? I think the most impactful would be:
Adding cross-references
Creating a troubleshooting section
Adding concrete success metrics
What would you like me to focus on?
User: Please do 1, 4, 5, and 6.
Sonnet: I’ll revise both documents to add cross-references, time estimates, experience-level guidance, and enhanced virtual/hybrid content.
I’ve made several key improvements to both documents:
Added Cross-References:
Included specific references between FAQ sections and checklist items
Added guidance notes linking to relevant FAQ sections
Connected virtual/hybrid content between documents
Added Time Estimates:
Included overall time investment guide in FAQ
Added specific time estimates for each checklist section
Provided buffer time recommendations
Adjusted estimates for first-time leaders
Added Experience-Level Guidance:
Created specific sections for first-time vs. experienced leaders
Added experience-level notes throughout checklists
Included different preparation recommendations based on experience
Added context-specific warnings for experienced leaders
Enhanced Virtual/Hybrid Content:
Added detailed virtual/hybrid sections to checklist
Expanded technology setup requirements
Included virtual-specific follow-up items
Added experience-level considerations for virtual sessions
Would you like me to:
Add more specific examples in any section?
Enhance any particular experience-level guidance?
Add more detail to the time estimates?
Expand the virtual/hybrid guidance further?
User: This is great. Thank you!
Sonnet: You’re welcome! Just to wrap up with a quick process note: both documents are written to feel substantial but approachable, with the FAQ addressing potential skepticism and the checklists providing concrete steps. The cross-referencing between them makes them work as a cohesive package while still being useful independently. The time estimates and experience-level guidance help set realistic expectations without being discouraging.
If you use these documents and find areas that need adjustment based on real implementation experience, feel free to reach out for updates. Good luck with the assimilation sessions!
Here’s the final output (FAQs and checklists) … if you click on the file, you’ll see they are very good (formatting aside, as we have not formatted them):

From start to finish, this exchange took about five minutes. It’s actually remarkable in several ways, beyond the quality of the work. We used no custom prompts. We provided no examples. And along the way, in addition to creating the content, Sonnet improved the work by suggesting ideas, including those it thought most effective. It also explained its thinking, stated new goals, and more.
First, and it’s not just an aside, if you are still investing lots of transactional labor creating content like this, it’s time to seriously reconsider the implications of AI for you and your team, and where you should be adding the most value in your organization. The ability of generative AI to quickly create excellent content is advancing far faster than most practitioners appreciate.
Second, since the 1980s scientists and philosophers have considered the Chinese room argument, which Sonnet described for us:
The Chinese Room argument, proposed by philosopher John Searle in 1980, is a thought experiment that challenges the idea that computers can truly understand or have genuine consciousness, even if they can appear to intelligently process language.
The thought experiment goes like this: Imagine a person who doesn't know Chinese is sitting in a room with a complete set of rules (in English) for responding to Chinese messages. When Chinese characters are passed into the room, this person consults the rulebook and follows its instructions to manipulate the symbols and produce appropriate Chinese responses. To someone outside the room receiving these responses, it would appear as though the person inside understands Chinese.
However, the person in the room is merely following syntactic rules to manipulate symbols without any actual understanding of their meaning. Searle argues this is analogous to how computers process language - they can follow sophisticated rules to produce apparently intelligent outputs, but don't truly understand or comprehend what they're doing in any meaningful sense.
The argument suggests that even perfect simulation of understanding (like passing the Turing test) is not the same as genuine understanding or consciousness. This remains an influential critique of strong AI and computationalism, though it has also faced various counterarguments over the years.
From this perspective, no, Sonnet is not reasoning. But there is another perspective, which is that from the person on the other side of the room — if it seems like the room understands Chinese, does it matter if it does or not? We asked Sonnet:
User: But from the perspective of the person on the other side writing in English, if it seems the room is thinking, isn’t it?
Sonnet: This is one of the most interesting counterarguments to Searle’s Chinese Room, sometimes called the “systems reply” or “emergent properties” response. The key insight is that while the individual person manipulating symbols may not understand Chinese, the entire system (the room + rulebook + person) taken as a whole might be said to understand Chinese in a meaningful way.
Think about it this way: When we say a human “understands” English, what we’re really observing is a complex system (the brain) that receives inputs and produces appropriate outputs. We can’t directly observe “understanding” — we can only infer it from behavior. If the Chinese Room system produces responses that are indistinguishable from a native Chinese speaker, what’s the meaningful difference between that and human understanding?
This connects to broader questions about consciousness and emergence. Just as individual neurons don’t “understand” English, but the collective system of neurons creates understanding, perhaps the individual components of the Chinese Room don’t need to understand Chinese for understanding to emerge at the system level.
There’s also an interesting parallel to how we learn language naturally — initially, we too are just pattern-matching and following rules we don’t fully comprehend, but genuine understanding emerges from this process. The line between “real” understanding and sophisticated symbol manipulation may be blurrier than Searle suggests.
That said, this remains an open philosophical question that touches on fundamental issues about the nature of consciousness, understanding, and what it means for a system to truly “think.” There’s no clear consensus among philosophers and cognitive scientists.
So is Sonnet reasoning? We don’t know. But whatever it’s doing, it seems different, more advanced, and more helpful than what we were using just a few weeks ago. We are putting it to good use, and think you should be, too. And we will remind you: Sonnet 3.5 New is, as of this moment, the worst and least thoughtful generative AI you will use for the rest of your life.
We think it will soon be time to, once again, start paying attention.
Thinking Fast and Slow With Generative AI
How to consider incorporating the new class of “reasoning” models into corporate communications workflows.
We wrote last week about the speculation that progress in frontier large language model development may be “hitting a wall.” We argued that even if progress does slow or even comes to a halt (which, again, we do not think is likely), the current generation of models can still provide immense practical value right now (our preceding piece shows some examples of what that looks like). That said, there is a parallel set of developments worth following: the development of so-called reasoning models. As we write above, leading models like Claude 3.5 Sonnet seem to be doing something like reasoning. We don’t know why that capability is emerging (specifically, whether it’s emergent or whether Anthropic has specifically tuned the model to behave in this way), but we do know that OpenAI and other labs are developing new models optimized specifically for problem-solving and multi-step reasoning.
OpenAI’s o1, announced in September, was the first publicly released model in this class. We wrote about it then:
o1 is important because it represents a shift in how OpenAI’s leading large language model (LLM), ChatGPT, works. As regular readers know, LLMs are prediction machines. They don’t search for and find answers — they create them, a few letters or words at a time, based on an unfathomably complex set of probabilities about what should come next based on what has come before in the sentence and conversation. They are, in essence, operating in a “stream of consciousness” mode. They do not plan, any more than you plan when you are in stream of consciousness mode. As a result, they make mistakes, and their ability to be “thoughtful” is limited (as smart as they seem).
…
o1 represents a significant shift from this approach. This model goes through a series of preceding steps to understand, deliberate about, plan for, and reflect upon your prompt prior to responding. This is called “chain of thought,” and there’s a good primer on it here. And while OpenAI does not show precisely what this pre-thinking is, it shows you descriptions of the steps and how the model generally did its reasoning.
Now, other labs are beginning to follow suit. Last week, Chinese firm DeepSeek introduced R1-Lite-Preview, with similar advanced reasoning capabilities. Others are likely to follow. While these models are impressive, it’s important to note that they are not superior to other models (like Claude 3.5 Sonnet or GPT-4) across the board of capabilities. o1 exceeds GPT-4 in its math and coding abilities, but not in writing, for example.
This is a key distinction to keep in mind as models continue to evolve and become more accessible. These two classes of models — one that operates in an automatic, “stream of consciousness” mode, and one grounded in a more analytical, step-by-step approach — resemble the two dominant modes of human thinking. These are known as “System 1” and “System 2” thinking, which were most famously described in Nobel laureate Daniel Kahneman’s 2011 book, Thinking Fast and Slow. Here’s a one-paragraph description of System 1 and 2 thinking as written by Claude:
User: Please create a one-paragraph explanation of System 1 and System 2 thinking as defined by Daniel Kahneman.
Claude 3.5 Sonnet: Daniel Kahneman's model of human cognition describes two distinct systems of thinking: System 1, which operates quickly, automatically, and with little conscious effort – handling tasks like recognizing emotions in faces or driving on an empty road; and System 2, which requires deliberate attention and mental effort for complex reasoning, careful analysis, and tasks that demand focus – like solving a difficult math problem or evaluating a complex argument. While System 1 excels at making rapid judgments based on past experiences and emotional associations, helping us navigate daily life efficiently, it can also lead to systematic errors and biases; System 2, though slower and more energy-intensive, serves as our analytical powerhouse, capable of catching and correcting these errors when activated, but requiring motivation and effort to engage. These systems work together constantly, with System 1 handling most of our daily decisions and System 2 stepping in when we encounter novel or complex situations that require careful consideration.
We can think of the new reasoning models as excelling in System 2 thinking. They’re better at analytical tasks and problem-solving, but not at everything. They’re not superior to the other class of models across the board, just as System 2 thinking is not superior to System 1 thinking in any ultimate sense.
All work, including the work of corporate communications, requires both types of thinking — and thus can benefit from using both classes of models. The art will increasingly lie in knowing when to switch between the two approaches, just as skilled communicators know when to trust their instincts and when to slow down for more methodical analysis.
To make this distinction practical, we asked Claude to come up with a list of corporate communications tasks aligned to each system:
Tasks that align with “System 1” style models:
Drafting initial versions of press releases, internal memos, and other routine communications where tone and flow matter more than precision
Adapting existing content for different channels and audiences, particularly where empathy and emotional resonance are key
Brainstorming creative campaign concepts or narrative approaches
Writing social media content that needs to feel authentic and conversational
Generating variations of key messages to test different approaches
Creating first drafts of speeches that need to sound natural and engaging
Developing storytelling elements that bring corporate narratives to life
Crafting responses to routine media inquiries where speed and tone are essential
Tasks that align with “System 2” style reasoning models:
Analyzing stakeholder messaging strategies, particularly when dealing with complex issues or multiple audiences
Fact-checking and verification of complex communications materials
Creating detailed communication measurement frameworks and analyzing their results
Developing crisis communication decision trees that require careful logic and systematic thinking
Breaking down complex corporate announcements (like merger communications) into structured message hierarchies
Conducting systematic content audits and gap analyses
Planning multi-phase campaign rollouts with intricate timing and dependency considerations
Mapping detailed stakeholder journeys and touchpoint analyses
We could quibble over some of the details, but we’d say that’s a directionally correct sample. Over the long run, we may see new models that are able to integrate these approaches, much as the human brain integrates System 1 and System 2 thinking. But we’re not there yet. In the meantime, as both classes of models improve and proliferate, getting the most out of generative AI for corporate communications will not just be about having better tools — but about knowing which to use, and when.
The Best AI Videos Aren’t Coming From Silicon Valley
While all eyes are on Sora’s imminent release, Kling shows us what AI video can already do.
The developments above, while compelling, are not the only ones we’re watching. Capabilities across modalities, including video, may be progressing even faster. We’ve been tracking AI-generated video capabilities since OpenAI’s Sora announcement made headlines in February. But while most developments in this space have focused on Sora’s yet-to-be-released capabilities, a Chinese company called Kuaishou Technology has quietly released what may be the most impressive AI video generation tool we’ve seen to date: Kling.
Over the past week we’ve been putting Kling through its paces, and the results have been notable. Kling produces video avatars with natural movements, facial expressions, and gestures. The emotional range of the avatars is what’s most striking — from subtle head tilts to convey thoughtfulness, to genuine-looking smiles that reach the eyes. These aren’t just improvements by a degree, they represent a marked advancement in quality.
Take the simple use case of creating a welcome video for new employees. Most AI video tools produce avatars that move robotically, making even the best ones feel somewhat uncanny. Unlike typical avatars, Kling's creations capture subtle human mannerisms—micro-expressions like weight shifts and natural blinking patterns—that typically go unnoticed, but make communication feel authentic. It handles transitions between emotions, too, with a smoothness we haven’t seen in other platforms.
But there’s a broader story here about how we’re tracking AI development. While the AI narrative has largely focused on U.S. companies like OpenAI and Anthropic, Chinese companies are making significant advances. Kuaishou Technology's success with Kling, along with DeepSeek's R1-Lite-Preview mentioned above, is proof of that AI innovation is happening on a global scale. The next breakthrough could emerge from any corner of the AI landscape, including China's rapidly evolving sector.
For now, Kling has set a new standard for AI-generated video. Its significance extends beyond its current technical edge to what it represents: AI-generated video has matured from an interesting prototype to a practical business tool. The transition from robotic avatars to natural, emotionally resonant video opens new possibilities for corporate communication—from employee onboarding to customer engagement. Organizations that begin exploring these capabilities now will be better positioned to adapt as the technology continues to evolve.
We’ll leave you with something cool: Suno has released its latest music generation model.
AI Disclosure: We used generative AI in creating imagery for this post. We also used it selectively as a creator and summarizer of content and as an editor and proofreader.When did the same with ChatGPT 4o we received an initial set of questions and answers followed by “Would you like me to refine this further or add specific examples?”
Did you happen to catch the Lex Fridman interview with Anthropic? I found the second interview with Amanda Askell fascinating when she was discussing how she's building Claude's character.