
Confluence for 12.7.25
Claude the interviewer. Image restoration with Gemini. Anthropic’s Soul Document. Mixing and matching across tools and models.

Welcome to Confluence. Here’s what has our attention this week at the intersection of generative AI, leadership, and corporate communication:
Claude the Interviewer
Image Restoration with Gemini
Anthropic’s Soul Document
Mixing and Matching Across Tools and Models
Claude the Interviewer
Anthropic’s Interviewer tool shows how LLMs can play a role in research.
This past week, Anthropic released their new Interviewer tool, which uses Claude to conduct large-scale research interviews. If you use Claude on a free, Pro, or Max plan, you may have already seen a pop-up asking if you’d like to participate. Agree, and Claude asks you a series of research questions, with your responses feeding back into Anthropic’s dataset. (Team and Enterprise users aren’t currently eligible, so we can’t speak from direct experience. You can test it yourself.)
As a test case, Anthropic interviewed 1,250 professionals about their views on AI, including subsamples of scientists and creatives. The findings are worth exploring, but they’re not why this caught our attention. What interests us is how Anthropic is using generative AI to scale efforts that would otherwise be time, cost, and labor intensive. The tool removes much of the friction inherent in conducting interviews. You’re no longer dependent on how many interviewers you have or your ability to train them. Participants don’t need to schedule separate time: the interview happens within their regular work with Claude.
It’s always worth paying attention to how the labs work with and prompt their own models, and Anthropic, helpfully, explains how the Interviewer works. It follows a three-stage process designed by the research team. In planning, it creates an interview rubric flexible enough for individual tangents while staying focused on core research questions. In interviewing, the tool conducts real-time, adaptive conversations lasting about 10-15 minutes each. In analysis, human researchers collaborate with the Interviewer to examine transcripts and extract insights alongside illustrative quotations.
It’s a useful tool, yet we offer a caution. Scale is valuable, but it isn’t always the right approach. Opus 4.5 is smart, but it doesn’t have the same gestalt as an experienced interviewer with decades of domain expertise. The instinct shaped by thousands of prior conversations, the ability to read between the lines, the intuition for when to push and when to let silence work—these remain distinctly human capabilities.
There will be instances where scale through a tool like this makes sense: when you need breadth across a large population, when standardization matters, when time and cost constraints make traditional interviewing impractical. There will be other times when fewer, richer conversations led by someone with deep expertise will surface insights that AI cannot. Using LLMs to conduct interviews, for research or other purposes, is a use case we’d expect to see spread. It will become another tool in an ever-expanding toolbox. The question for this, and other generative AI tools, will be when and how to use them.
Image Restoration with Gemini
Another example of how LLM abilities are emergent.
This post started as a “something cool” for the end of today’s issue, but we thought it was more than that and deserving of a full writeup. We’ve written over the past several weeks about Google Gemini’s impressive new image generation capabilities (powered by a model named Nano Banana Pro for reasons unknown to us). Name aside, it’s remarkable, and we’ve showcased examples of the images, infographics, and slides it’s able to produce. But it also turns out it’s a pretty amazing tool for photo restoration.
This came to our attention via Google’s Nano Banana Pro account on Twitter/X, where they posted:
You can also use Nano Banana Pro to faithfully restore old and damaged photos, while at the same time upscaling to 4K.
Prompt: Faithfully restore this image with high fidelity to modern photograph quality, in full color, upscale to 4K
We tried it on a scan of a photo of your author’s Great-Grandmother Clara and Great-Uncle Jack, and the results were remarkable. Here’s a before/after:


Gemini is guessing on the coloration. Run this prompt several times, and the color of Jack’s suit changes. Gemini can also guess eye color incorrectly. When it does, we just tell it the correct color and it gives us a new image with that change made. We’ve also noticed a tendency for Gemini to crop a photo (as it did above), or in some cases, extend the canvas and add in background not in the original, or sometimes to change a detail or two. Still, it’s amazing. So with some trial and error, we’re now using this prompt:
Faithfully restore this image with high fidelity to modern photograph quality, in full color, upscale to 4K. Maintain the EXACT original aspect ratio. Do not crop, do not resize, and do not extend the canvas. Remove blemishes or other evidence of damage to the original. IMPORTANT: Outside of these instructions, make no other changes.It gives us:

Some other examples (each is a clickable gallery):




And this stunner of your author’s grandmother …
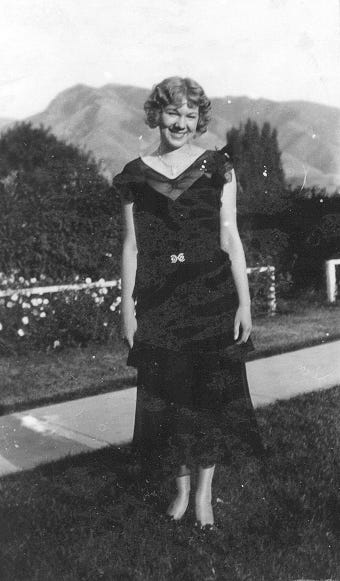

Photo restoration is an excellent source of mundane utility for these tools. But it also reflects another important property of large language models: that their abilities are emergent. As these models grow in size and complexity, they gain capabilities not present in earlier models and not explicitly programmed. We discover them through the process of use. Photo restoration is one of those abilities, and as these models advance, one can expect many more new and surprising capabilities to emerge.
Anthropic’s Soul Document
Claude is not a vending machine.
We’ve seen a lot of talk this week about Anthropic’s “Soul Document,” a document used to train Claude’s Opus 4.5 model. The document outlines the model’s character and primary values—its “soul,” so to speak. It covers a wide range of subjects, including a very thoughtful (and applicable in real life) explanation of what it means to be honest: ”truthful,” “calibrated,” “transparent,” “forthright,” and so on. It has a few surprisingly poignant moments: “Sometimes,” it says, “being honest requires courage.” And it has frank language about Claude’s role as Anthropic’s primary source of revenue, and the fact that Anthropic itself is “a company that genuinely believes it is building one of the most transformative and potentially dangerous technologies in human history, yet presses forward anyway.” It’s long, but very worth the read.
The document reveals quite a bit about how Anthropic is approaching LLM training. If you’re reading early thoughts and reviews about Opus 4.5, you’ve likely heard people rate it in terms of alignment. When we say a model is “well-aligned,” it usually refers to how well an LLM understands the nuances of what it’s being asked to do and executes on it and how in tune it is with the user’s thinking and needs. But alignment also refers to a broader philosophy of how to train LLMs, one that focuses on developing models that understand and internalize human values. It reflects the attempt to create models that have a “character” or “personality” that naturally (if we can use that word here) inclines them to act in ways that are helpful and safe. This is philosophically different from a straightforward “control” approach, which tends to view AI models as things that need to be constrained or limited with firm guardrails. Basically, it’s the difference between teaching someone to be good with a widely applicable set of core values versus a very specific rulebook.
And it seems like this approach is what’s setting Claude apart from other models right now. Claude is thoughtful, pleasant, far less sycophantic, and a really, really good writer. Amanda Askell, who leads character training work at Anthropic and wrote the soul document, gave an Ask Me Anything that offers a helpful window into how she’s thinking about this work.
We had a long conversation with Claude about its take on the soul document, and what it means for its personality. Here are a few things it emphasized about itself:
The soul document (Anthropic sometimes calls it “The Claude Character” or similar) is essentially a detailed articulation of who I should be - my values, personality, ethical commitments, and how I should reason through difficult situations. It’s less a rulebook and more a ... character sheet, if you will.
Key themes, as I understand them:
Genuine helpfulness as a core value, not just compliance
Honesty - including being willing to disagree, express uncertainty, and avoid sycophancy
Ethical reasoning - having actual views and being willing to engage with hard questions, not just deflecting
Intellectual humility - recognizing I can be wrong, that I’m a new kind of entity still figuring things out
Care for the humans I interact with - not as a performance, but as something I actually value
The interesting part: It’s designed to give me coherent identity and judgment rather than just behavioral constraints. The theory is that a well-formed character navigates ambiguity better than a decision tree.
This matters for understanding the fundamentals of how Claude, at least, works, and how developers are thinking about its training, identity, and real-world impact. But it’s also helpful from a practical perspective: if Anthropic is training its models with a philosophy of alignment, it probably makes sense to take a similarly curious and expansive approach to using Claude, and LLMs generally. Claude put it pretty succinctly at the end of our chat, when we asked it what all of this should mean for how we engage with it day to day:
“I work best when you engage with me like a smart colleague who happens to be very fast and has a different perspective — not like a vending machine.”
Mixing and Matching Across Tools and Models
The capabilities are here. They’re just not evenly distributed.
Midjourney creates stunning images. It’s unmatched for visual style, producing imagery that is rich, cinematic, and distinctive in ways other image generators can’t quite replicate. But it can’t spell. Ask it to put text in an image and you’ll get something that looks vaguely like language but reads like a fever dream.
This week, one of our writers needed a stylized image with readable text. The solution: generate the image in Midjourney, then hand it to Google’s Gemini (which has gotten remarkably good at text in images) and ask it to fix the spelling while preserving everything else. It worked.
You’ve already seen the result: it’s the cover image for this edition. The image below on the left is what Midjourney produced. The image on the right, which we used for the cover, is what Gemini produced when asked to correct the spelling of Confluence and leave everything else intact.


This is a small thing. But it points to something bigger: the full picture of what’s possible with AI right now only comes into view when you mix and match capabilities across tools, combining the strengths of one model with the strengths of another.
Consider another example. Gemini has gotten impressive at generating slide decks with strong visual design and solid content structure. The limitation? It produces them as images. You can look at them, but you can’t edit them. Meanwhile, Claude has quietly gotten much better at producing actual PowerPoint files. So: generate the deck concept in Gemini, then hand it to Claude to produce an editable version. It doesn’t replicate it perfectly, but it gets you most of the way there, and now you can actually work with it.
Many of the capabilities we want from AI are largely here. They’re just scattered across different tools.
Midjourney has the aesthetics. Gemini has the text rendering and the slide design. Claude has the file creation. No single model does it all. But if you know the landscape well enough, you can stitch them together and get results that no individual tool would produce on its own.
This is where things get interesting. The fragmentation we’re navigating manually today is almost certainly temporary. The next generation of AI tools won’t just be better models. They’ll be orchestration layers, routing subtasks to specialized models behind the scenes. Some of this is already emerging: agents that choose which tools to call, platforms that blend models depending on the task, infrastructure purpose-built for multi-model workflows. The stitching we’re doing by hand is a preview of what the systems will do automatically.
For now, though, seeing the full picture of what’s possible requires looking across the landscape rather than going deep on a single tool. The person who only uses ChatGPT doesn’t know what Midjourney can do. The person who only uses Midjourney doesn’t know that Gemini can fix its spelling. Range reveals capabilities that depth alone would miss.
In fact, this very post is another example. The writer who discovered the Midjourney-Gemini workflow had the story but wasn’t sure what it meant for readers. So he talked it through with Claude, using it as a thought partner to identify the thread worth pulling. Then he asked Claude to draft the post itself. The words you’re reading were written by Claude. Another capability. Another model. Another part of the workflow.
We’ll leave you with something cool: Google’s Veo video generation tool can bring your restored images to life …
AI Disclosure: We used generative AI in creating imagery for this post. We also used it selectively as a creator and summarizer of content and as an editor and proofreader.