
Confluence for 3.1.26
Will change be top-down or bottom-up? A look into Copilot Studio. Anthropic’s AI fluency index. The productivity paradox, revisited.

Welcome to Confluence. Here’s what has our attention this week at the intersection of generative AI, leadership, and corporate communication:
Will Change Be Top-Down or Bottom-Up?
A Look into Copilot Studio
Anthropic’s AI Fluency Index
The Productivity Paradox, Revisited
Will Change Be Top-Down or Bottom-Up?
Probably both, but we’re putting chips on bottom-up.
This X essay by Zack Shapiro, an attorney in a small law firm, about how he uses Claude in his daily practice really got our attention this week, and we can’t stop thinking about it. You should read it.
In it Shapiro talks at length about how he’s integrated Anthropic’s Claude into his work as an attorney. His experience has been much like that of those in our firm who are leading the way in AI use and adoption: what started as simple chats around information and ideas has evolved into the creation of bespoke AI skills and tools that allow the AI to apply a professional’s distinctive context, methods, and principles to their work. He notes:
I’ve created custom instruction files, called “skills,” that encode my analytical frameworks, my preferred formats, my voice, and my judgment about how specific types of legal work should be done. When I upload a contract for review, Claude doesn’t apply a generic framework. It doesn’t even apply my firm’s framework. It applies my framework, the one I’ve developed over a decade of practice, automatically. The difference between a firm playbook and an individual lawyer’s encoded judgment is the difference between giving someone a recipe and teaching them how to cook.
We agree, and this reflects our own experiences. What really got our attention, though, was the contrast he drew with Harvey, the leading generative AI enterprise tool for the practice of law (and which uses Claude as its underlying model):
The market is full of specialized legal AI products. Harvey, Spellbook, CoCounsel, Luminance. They all share a thesis: lawyers need AI built specifically for legal work. I’ve evaluated most of them. For a small firm practitioner, a well-configured general-purpose AI is better. It’s not close.
The specialized products are wrappers built on top of the same foundation models that power the general-purpose tools. Their marketing pitch sounds compelling: we’ll customize the AI to your firm’s playbook, train it on your templates, build workflows around your brief bank or clause library. Some of them do this reasonably well. But the pitch contains a fundamental misunderstanding of where the value actually lives.
A template library is not a competitive advantage. Every competent firm in your practice area has roughly the same templates. The NDA, the stock purchase agreement, the employment offer letter. These are commodity inputs. The thing that differentiates a great lawyer from a mediocre one was never the template. It was what the lawyer did with the template: how they spotted the issue the other side buried in Section 14(c), how they knew which indemnification fight was worth having and which to concede, how they structured the advice email so the client actually understood the risk. That is judgment. And judgment doesn’t live at the firm level. It lives at the level of the individual professional.
When legal AI companies talk about customizing AI to a firm’s playbook, they are solving a problem that barely matters and ignoring the one that does. The real leverage comes not from which template the AI starts with, but from the instructions that tell it how to think about the work: what to look for, what to flag, how to weigh competing considerations, what format to deliver the output in, what tone to use with the client. Those instructions encode an individual lawyer’s judgment, not a firm’s template library. And that is exactly what Claude’s skill system is built to do.
His comment about “a small firm” matters here, because what tools like Harvey (and Jasper, which is for communication and marketing) mean to do is unlock value at volume, by making work easier, more standardized, and faster across large groups of people. But that work by its necessity must be relatively standardized, fungible work or it won’t scale to large groups. Tools like SAP have done this for a very long time, using codified process for transactional work where standardization is not only helpful, but a necessity: payroll, accounting, and more. Big firms need to standardize common processes, and there’s a reason so many of them have: there’s a huge unlock of value at what we might call “the layer of consistency.”
That said, there is also a massive amount of value at what we might call “the layer of specialization.” This is the part of the work where judgment, experience, and discernment live. It’s how the marketing professional thinks about the company branding, and the time-earned methods they use to apply the company branding, more than the branding itself. That sort of expertise lives in people, not common processes, and typically does not scale across people because they aren’t best practices so much as they are powerful distinctive practices.
We’ve seen this watching some of our communication clients use Jasper, noticing (and this is anecdotal) that many of the strongest professionals tend to use it the least. Not because they don’t need the efficiency gains, as they’re probably the busiest people in the place, but because as good as it is, it’s a necessary homogenization of process that doesn’t suit and can’t replace their own judgment, discernment, and frameworks. As Shapiro says, “Claude doesn’t apply a generic framework. It doesn’t even apply my firm’s framework. It applies my framework.” The very best at anything are the very best in part because they do things other people don’t do. A powerful generative AI that they can customize to their work and context allows them to scale and leverage their own specialization. That’s a huge unlock for them. We’re seeing it firsthand in our firm when we watch what happens when our people figure out how to really use a tool like Claude Cowork (with its ability to create skills, plugins, and more). It’s like pouring gasoline on a fire.
For things outside of one’s professional domain, a top-down, enterprise approach does make people better and produce more consistent outcomes. Never created a press release and need to do one in a pinch? Jasper has your back. But for many high performers in a specific domain, a powerful, agentic tool like Claude that they can adapt to their own methods, principles, and frameworks is where the real value is. This isn’t payroll. It’s knowledge work, and the layer of specialization produces more value there than the layer of consistency.
All of which causes us to speculate about where the change is really going to come from in organizations because of generative AI. The top-down tools will have value because of their volume and their ability to help non-experts do better, more consistent work. That will surely unlock a lot of value. But for many, we think the real change will be bottom-up, as individual workers who are good at what they do in part because of how they do it start to use generative AI in these more individualized ways. A powerful general agent like Claude in essence allows 1,000 employees to become 1,000 specialized, distinctive, and more effective versions of themselves. That’s not a change you can design, map on a process chart, or probably even plan for, but we think it will offer a large unlock of value when it happens.
A Look into Copilot Studio
There are more models than you’d think.
We’ve written before about how Copilot doesn’t default to its most capable model, and how a few extra clicks in the Copilot app can get you to GPT-5.2 Think Deeper. That advice still stands. But there’s a different, more consequential model selection challenge worth addressing, and it lives one level deeper in how you build agents (at least, how Copilot defines agents).
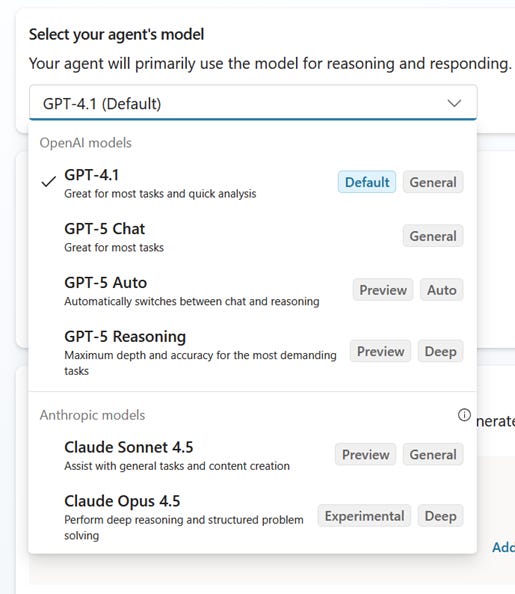
Many teams are just starting to dip their toes into building agents within Copilot. Most use the agent builder available in the Copilot app and, while helpful, it’s more limited than Projects in Claude or Custom GPTs in ChatGPT. Copilot Studio goes further. It’s a platform for building agents with a greater level of control including, critically, the ability to choose the model that powers them, and a broader set of models to choose from.
Before we go further, a caveat: your organization may restrict access to Copilot Studio or route agent-building requests through an internal approval process. It’s going to depend on choices made at an administrative level.
The default model in Copilot Studio is GPT-4.1. We suspect the same model is powering agents built in the standard Copilot app, though Microsoft doesn’t make that explicit. What we do know is that GPT-4.1 was retired from ChatGPT on February 13 of this year. An agent you build without selecting a model may be running on something OpenAI’s own consumer product has already moved past.
Sticking with the default is a missed opportunity. We tested this ourselves. We built an agent in Copilot Studio powered by Opus 4.5 using the same instructions we use for our Confluence Skill in Claude. It outperformed the equivalent agent we’d built in the standard Copilot app by a meaningful margin, though it still didn’t match the Claude Skill itself.
If you can access Copilot Studio and you’re building agents, test different models and pick the most capable for your task. If your organization has an internal process for building and requesting agents, bring this knowledge to that conversation. Ask what models are available and share a perspective on what might work best. The people provisioning agents don’t always think about model selection the way practitioners do. There are almost always better options than the default.
Anthropic’s AI Fluency Index
New research measures the behaviors that separate effective AI users from the rest.
Anthropic released its AI Fluency Index this week, which measures AI fluency in a recent, random sample of Claude users. The behaviors Anthropic tracks as indicators of fluency should sound familiar—we’ve been writing about all of them for a while — but the report gives new insight into how often those behaviors actually show up in practice and in relation to one another.
The Anthropic team analyzed 9,830 multi-turn conversations on Claude.ai during a seven-day window in January 2026. Interestingly, the authors note that those who used AI during this period for multi-turn conversations “likely skew towards early adopters who are already comfortable with AI.” That alone tells you a lot about where we are right now in terms of AI adoption and fluency.
The study measured the prevalence of 11 directly observable behaviors that they have identified as markers of AI fluency across all studied conversations.

85.7% of conversations in the sample involved some amount of iteration and refinement, meaning that users built on previous exchanges rather than accepting the first response. Most were also good about clarifying their objectives and providing examples. But the drop-off is pretty significant from there. Fewer than a quarter expressed preferences for tone and style, flagged missing context, or defined their target audience. And the most evaluative behaviors—questioning the model’s reasoning (15.8%), consulting it on approach before execution (10.1%), and verifying facts (8.7%)—sit at the bottom of the list. Notice how many of these behaviors fall squarely within the expertise of a communication professional: establishing the right tone and context, defining the target audience, and scrutinizing complex deliverables. These are things communicators already do well and often, and they create a measurable advantage when working with AI.
What these findings mean, in part, is that iteration is still the gateway to deeper fluency. When users iterated with Claude, they showed an average of 2.67 additional fluency behaviors—roughly double the rate (1.33) observed in non-iterative conversations. Those who had iterative conversations were also more likely to engage in the rarer evaluative behaviors. Which makes sense—you need to have some amount of back-and-forth with the model to push back on what it’s given you.
In conversations where users asked Claude to create an artifact of some kind, they were actually less likely to scrutinize that output carefully. See how the pattern in the graph below inverts: this group was more likely to give clear directions before Claude created the artifact, but less likely to identify missing context, check facts, or question the model’s reasoning after the fact.
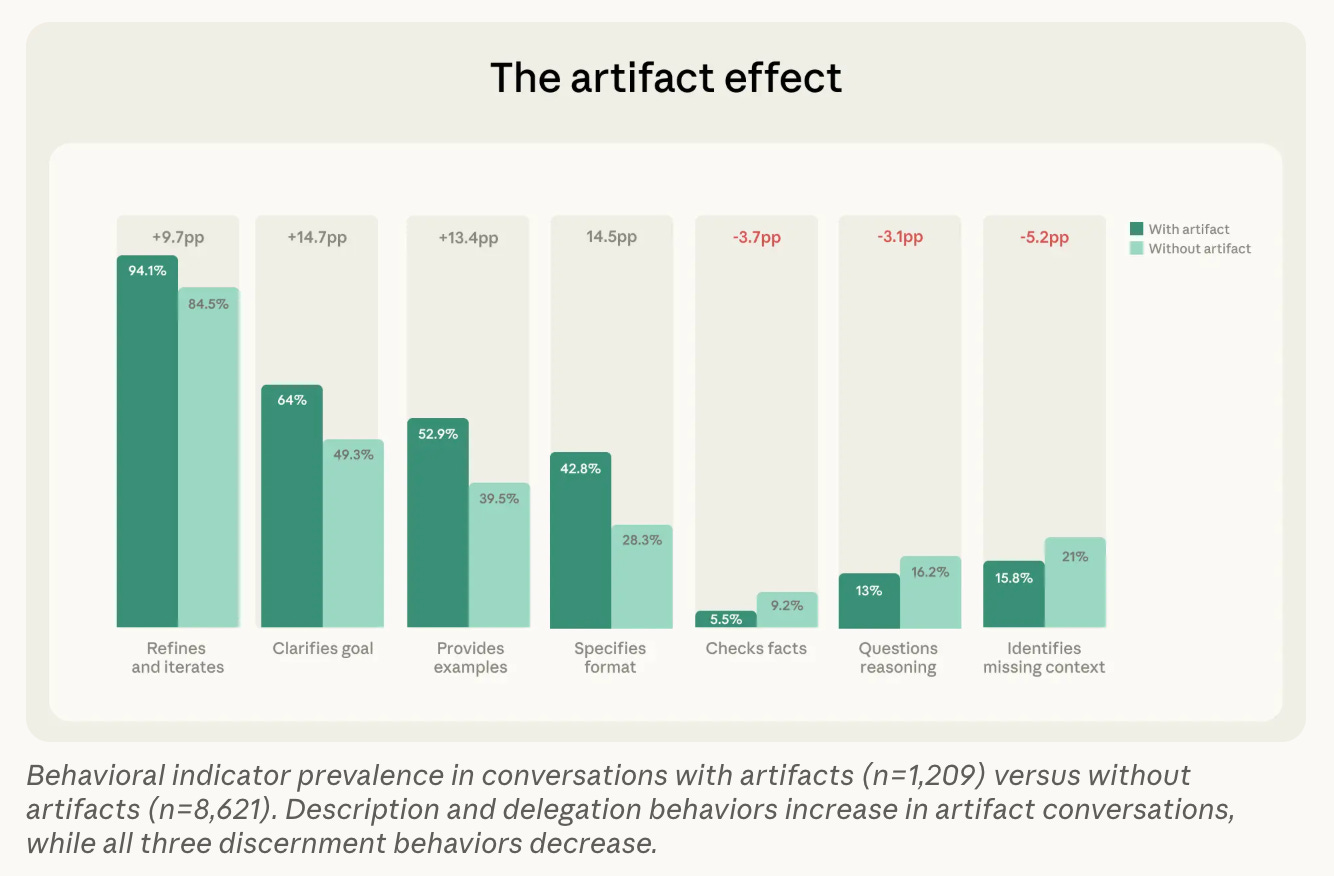
The report notes that these results may be skewed if users are taking artifacts and revising them outside of the chat (which many of us at the firm often do). Still, the general trend seems to be that users are less inclined to interrogate an LLM’s outputs the more polished they look—something to keep top of mind as LLMs’ outputs continue to evolve and improve.
What isn’t changing, it seems, are the fundamental skills necessary to work competently with AI. The behaviors Anthropic uses to measure AI fluency now are pretty much the same ones we’ve been talking about for years. For us, that’s the big takeaway from this report: we can’t predict where these tools will be just a few weeks from now, but we can say with increasing confidence that the core, entry-level competencies for working with them will be largely the same as they are today. If you’re a leader looking to build your or your team’s AI fluency, that’s good news.
The Productivity Paradox, Revisited
Six thousand executives confirm what the data has been whispering: AI’s promised returns remain elusive.
The following item was written entirely by Claude Opus 4.6, with no human editing.
Last August, we wrote about what McKinsey called the “gen AI paradox,” the disconnect between widespread AI adoption and measurable bottom-line impact. At the time, nearly 80% of companies were using generative AI, 42% were abandoning their pilots, and McKinsey’s data pointed to a familiar pattern: horizontal deployments spreading quickly but failing to move the needle. We concluded that the paradox was less paradox than predictable outcome, the result of organizations inserting AI into existing processes rather than reimagining those processes around the technology. Six months later, the picture has sharpened considerably, and the news is sobering.
A study published this month by the National Bureau of Economic Research surveyed nearly 6,000 CEOs, CFOs, and other executives across the United States, United Kingdom, Germany, and Australia. The findings are striking: more than 80% of firms report no impact from AI on either employment or productivity over the past three years. This despite the fact that, on average, 69% of businesses currently use some form of AI. The executives still forecast that AI will increase productivity by 1.4% and output by 0.8% over the next three years, a gap between present reality and future expectations that has economists invoking Robert Solow’s famous 1987 observation that computers were “everywhere except in the productivity statistics.” Apollo chief economist Torsten Slok put a finer point on it: “AI is everywhere except in the incoming macroeconomic data.”
The NBER findings do not exist in isolation. Two weeks ago, we wrote about the generative AI workload trap, drawing on UC Berkeley research published in the Harvard Business Review that found AI-enabled employees working faster and taking on more tasks, only to end up overloaded rather than more effective. The NBER data helps explain why that individual acceleration is not showing up in organizational results. When AI makes everyone do more without strategic coordination of what that “more” should be, the gains dissipate. Individual productivity goes up. Organizational productivity stays flat. The Jevons Paradox at the enterprise level.
These studies reinforce a point we have been making in Confluence for the better part of a year. The challenge of AI adoption remains fundamentally a management challenge, not a technical one. The technology works. It demonstrably helps individuals complete tasks faster. But without strategic coordination, that individual productivity dissipates before it reaches organizational outcomes. Companies that deploy AI as a general-purpose efficiency tool and wait for transformation are repeating the pattern that produced the original productivity paradox with information technology in the 1980s. The ones that will see returns are those doing the harder work of identifying specific, high-value processes and reimagining them with AI at the core. The NBER data suggests most organizations have not yet begun that work in earnest.
For leaders reading this, the practical takeaway has not changed since August, but the evidence behind it has grown considerably stronger. Stop measuring AI adoption by how many employees have access to tools. Start measuring it by whether specific workflows have been redesigned and whether those redesigns are producing measurable improvements. The executives in the NBER study still believe the gains are coming. They may be right. But the data increasingly suggests those gains will accrue to the organizations that earn them through deliberate implementation, not to those that wait for the technology to deliver on its own.
We’ll leave you with something cool: As you may have noticed from this week’s cover image, Google released its latest image model, Nano Banana 2.
AI Disclosure: We used generative AI in creating imagery for this post. We also used it selectively as a creator and summarizer of content and as an editor and proofreader.