
Confluence for 5.31.26
Hello, Opus 4.8. The helpful ghost. When AI's tells run deeper. An excellent interview on the state of enterprise AI.

Welcome to Confluence. Here’s what has our attention this week at the intersection of generative AI, leadership, and corporate communication:
Hello, Opus 4.8
The Helpful Ghost
When AI’s Tells Run Deeper
An Excellent Interview on the State of Enterprise AI
Hello, Opus 4.8
Anthropic releases an update of its most powerful public model.
They just keep coming. Not long after the release of ChatGPT-5.5 by OpenAI, this past week Anthropic released Opus 4.8, its most powerful public-facing model.
We’ve been using Opus 4.8 all week, and it’s a very good model indeed. The hot take: less strident than Opus 4.7, and a better conversationalist and writer (although it still has favored metaphor tells like “move,” though it’s easy for one to tune those out of its behavior with custom preferences or style guides).
The biggest change we see from Opus 4.7, though, is that 4.8 just seems smarter, in a practical way. Now, 4.7 is smart. When it came out we were all about how smart 4.7 was. But working with 4.8 feels like working with an appreciably savvier and more intelligent agent. For us this difference has shown most in judgment and observation. Opus 4.8 notices things 4.7 would not notice, seems to draw better and more subtle conclusions, and when faced with decisions, seems to make better calls about what to do or not do (especially important if you’re asking the model to act as an agent that makes decisions as it works).
To show a bit of what the model can do, we gave Opus 4.8 the following prompt using “extra” reasoning:
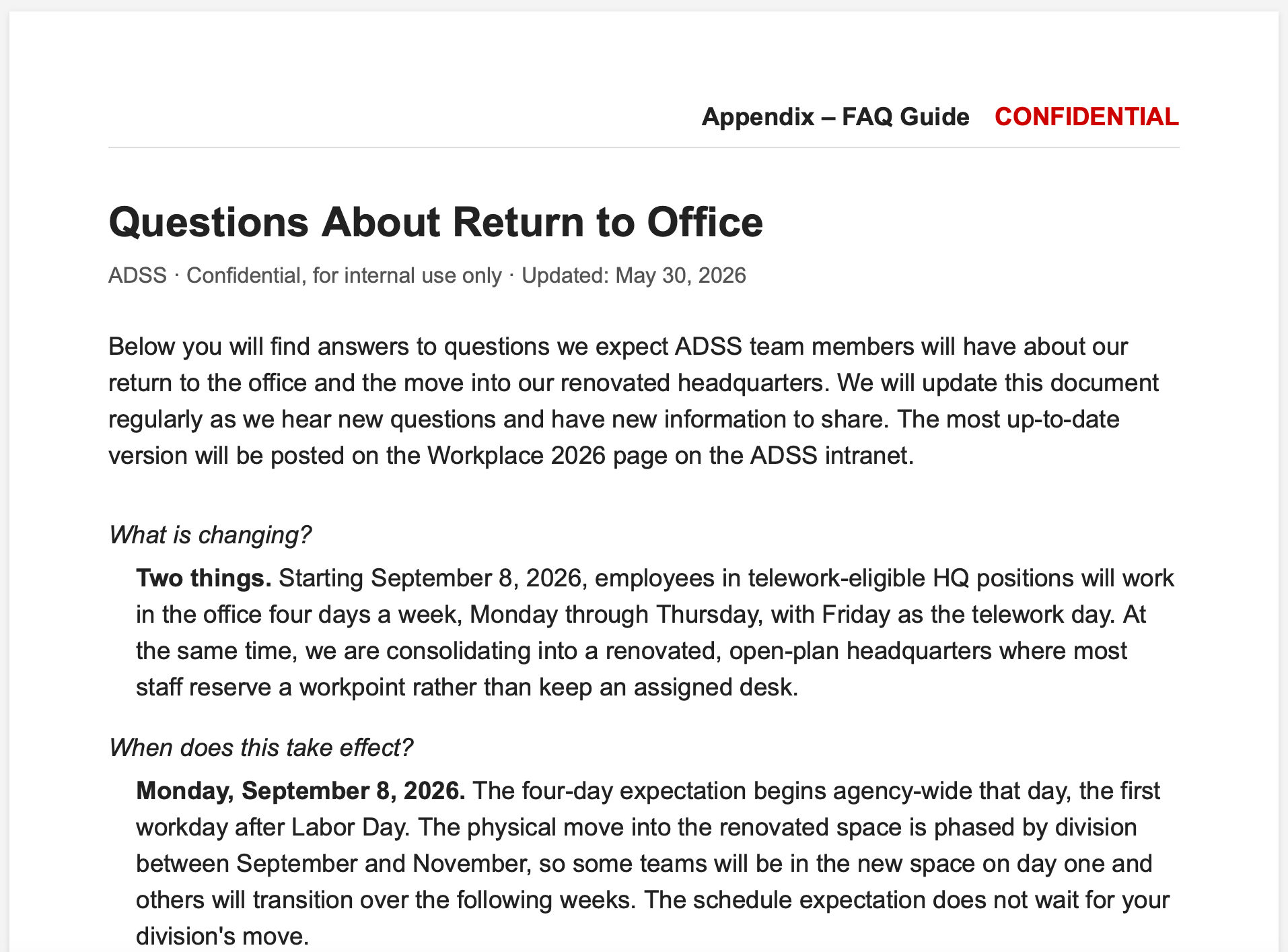
This is a test of your ability as an internal communication strategist and creator of employee-facing content. First, construct for yourself a detailed and realistic case study of an organization in the public sector located in Washington, DC, that is asking its employees to return to office. Which organization you select (or invent) is up to you. The overall situation is that employees have been able to work from home with flexibility since COVID, but now are being asked to return to the office four days a week and to work in an office plan. The case that you construct for yourself must be sufficiently detailed that it will allow you to complete the second step of this process, which is to hypothesize the FAQs that employees will have and leadership will need to answer, and then to create a comprehensive FAQ document using our FAQ writer skill. Don’t ask any questions. The rest is entirely up to you. Save the final FAQ document in a place where I can find it as both a Word document and an HTML file. Go.
This test used an in-house skill we have for creating FAQ materials per our firm’s standards. The model churned away for a few minutes, then delivered all materials as asked with a case it invented for “the U.S. Agency for Data and Statistical Services (ADSS), a fictional independent federal statistical agency in DC.”
Here’s the output in Claude Artifact links. Click the hyperlinks to see each deliverable in full.

Then, for fun, we asked 4.8 to “build an employee-facing website about the change.” Here’s that output:
Claude’s Employee-Facing Website
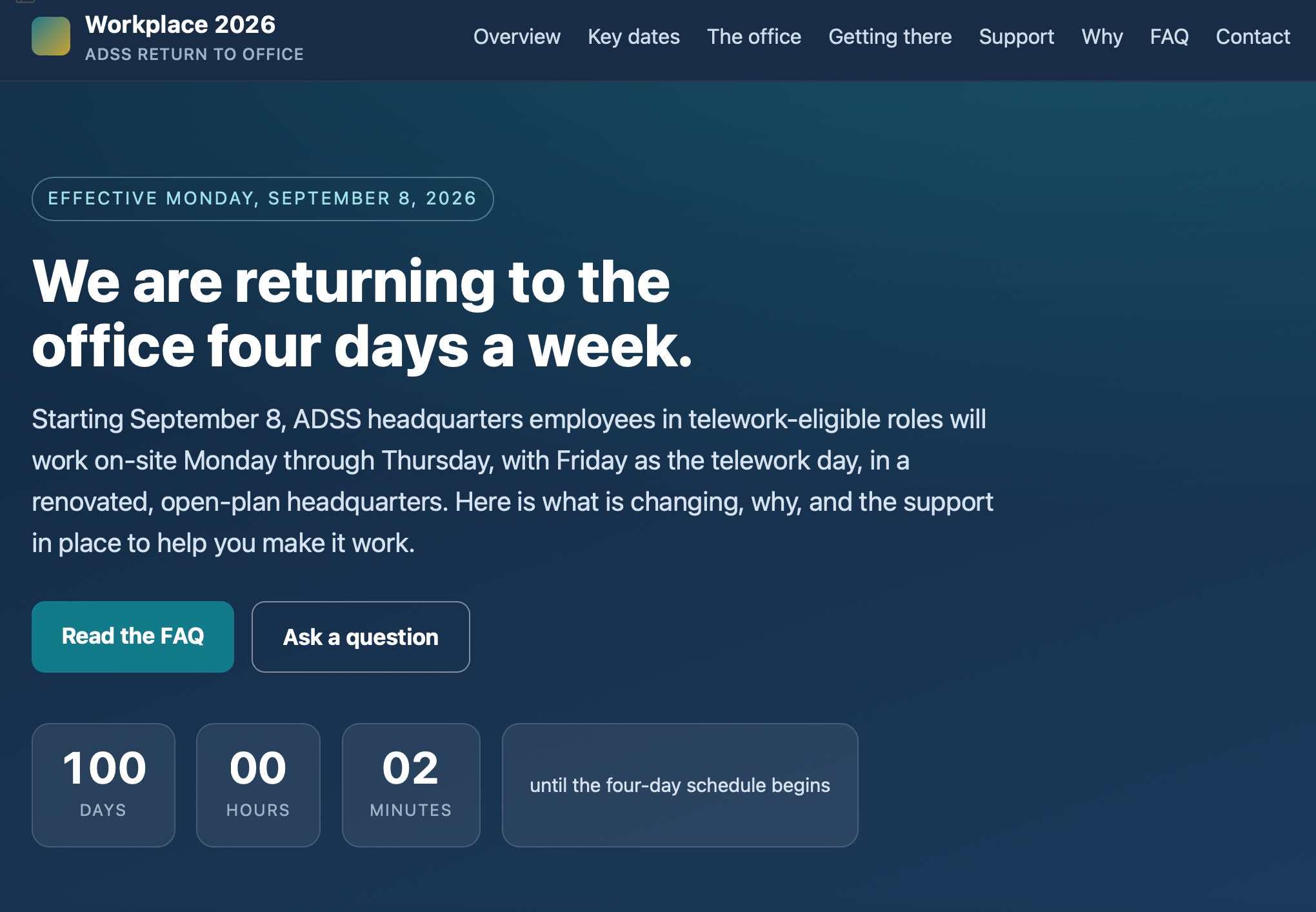
Total time for Opus 4.8 to create all this material? Maybe five minutes.
We ran the same test with Opus 4.7, and we saw better judgment and intelligence in 4.8’s output. 4.8 also more closely adhered to the formatting standards for the FAQ document based on our template (which 4.7 generally ignored).
So, yes, it is a very good model and a step up.
And speaking of the step up, also notable is that Anthropic released 4.8 just six weeks after it released 4.7. We used to go months between model releases. Now they’re coming about every 40 days. It also sounds like Anthropic is close to releasing an update for its Sonnet models and, according to some rumors, a public-facing version of Mythos (the model so capable they’ve withheld it so software and hardware developers have time to harden their cybersecurity infrastructure against it).
To illustrate this increasing release pace, we asked Opus 4.8 to create data visualizations of the Opus release history, including formal GPTval-AA Elo scores (a benchmark of artificial intelligence) for those models that have them, using a skill we have that applies Ed Tufte’s information design principles to data visualization. Opus 4.8 built these for us:
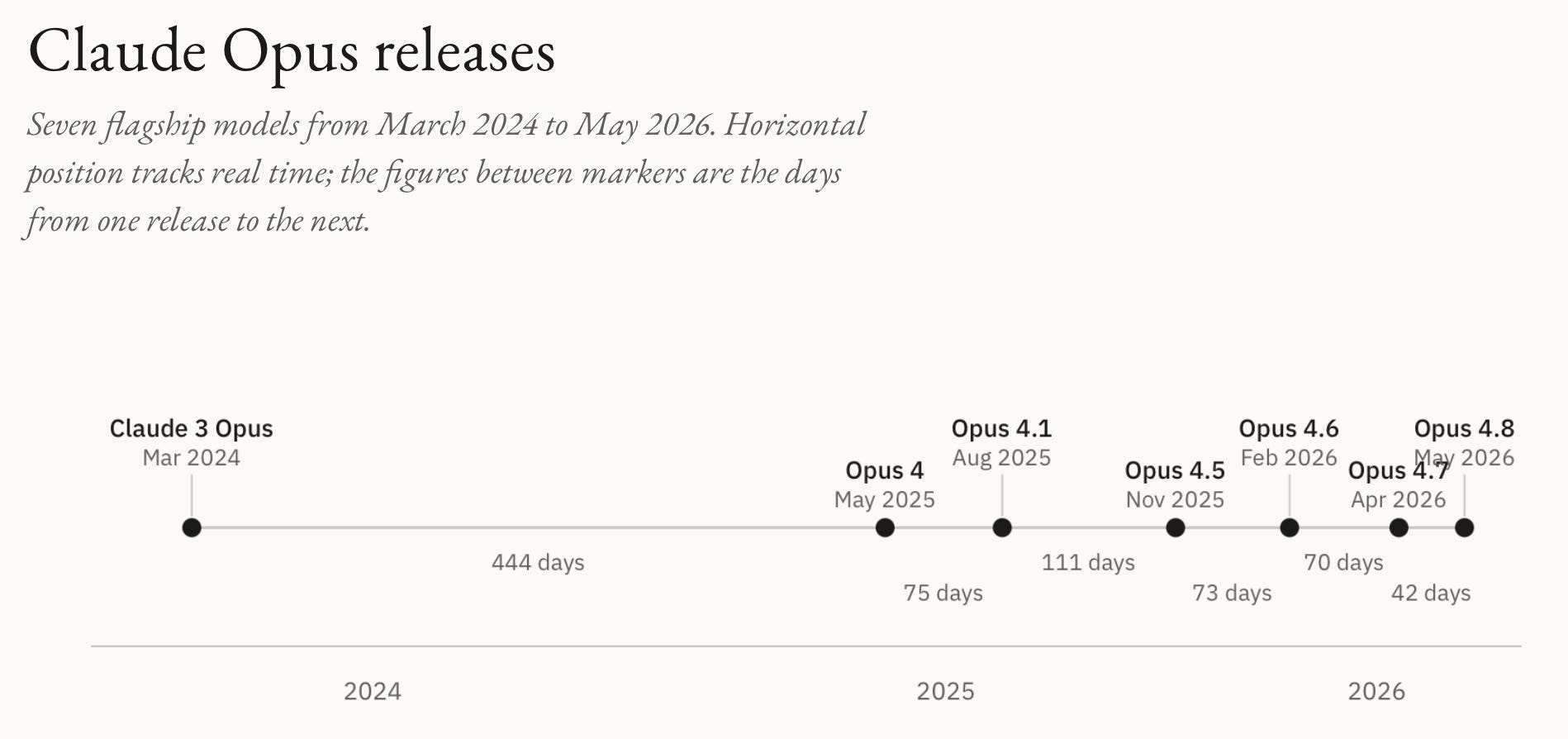
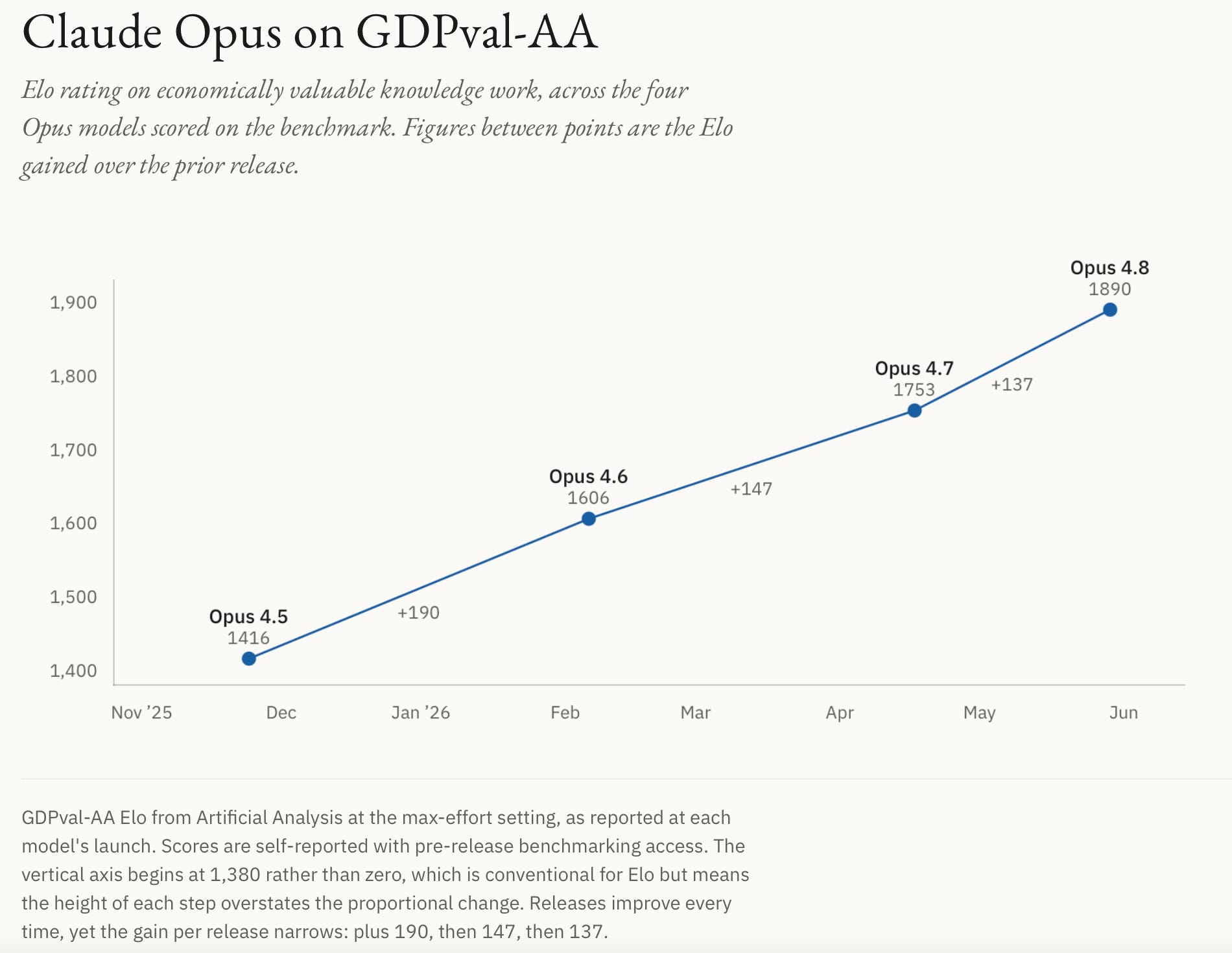
As the charts show (in a very Tufte-esque way), release cadence is compressing (about 73 days from 4.5 to 4.6, then 70, then 42), while the per-release Elo gain is shrinking (+190, +147, +137). Faster shipping with smaller individual steps, but as you can see from the overall trend, things are not slowing down, and in fact, they’re speeding up.
When AI’s Tells Run Deeper
Revising away the em dashes isn’t enough.
We’ve written much about AI tells in recent weeks, whether in visual design or in writing. And for good reason. The quality of outputs from frontier models is high, more people are comfortable using them, and it is simply easier to default to those outputs than to tailor them to our own voice or sense of taste, despite the risks of outsourcing our judgment or missing obvious mistakes in the process.
On the surface, the obvious tells are easy enough to avoid. Revising prose so it drops the em dashes and stops talking about the “moves” we should make, or steering a model away from its default slide style, takes relatively little effort. But what happens when the patterns in AI-generated content run deeper?
A team from the University of Maryland and Google DeepMind built a tool that analyzes the underlying structure of short stories. They ran more than 60,000 stories through it: one human-written story plus five AI versions (Claude Sonnet 4.6, GPT-5.4, Gemini 3 Flash, DeepSeek V3.2, and Kimi K2.5) for each of roughly 10,000 prompts. Setting writing style aside entirely, they found that AI models leave real structural tells in how they build a story. Relative to human authors, AI models tend to over-explain the story’s moral point and to favor single-track plots with tidy resolutions. Human authors are more likely to leave threads unresolved, address the audience directly, and present morally ambiguous protagonists. The models, even as they resemble one another more than they resemble human authors, also carry their own signatures. Claude has a fondness for epilogues. ChatGPT often uses rumor as a plot device. Gemini’s stories were most often tagged as bleak or oppressive.
This reinforces something we have been discussing with clients for a while. When we write with AI, we have to mind the line between making our own decisions and letting the model make them for us. The stylistic decisions are the easy ones to catch. If Claude leans too hard on the “moves” we should make, or defaults to its own slide style, we can see it and cut it, and the labs can tune it out of the next version. The structural decisions are the harder problem. They sit below the surface of the prose, which makes them tougher to notice, and the researchers suggest they may be tougher for labs to train away, because they are baked into how a model builds a story rather than how it phrases one.
As the models get more capable and we rely on them more, polishing surface style is no longer enough. The value we add lives in the structural calls. It is in what we leave unresolved, what we refuse to explain, whose perspective we inhabit. That is harder than swapping out an em dash, and the model cannot reliably do it for us. It also means resisting the model when it offers to help. Ask AI to improve a draft and it will reliably smooth out the very things that mark the writing as ours, the open question we left unanswered, the tradeoff we admitted rather than buried, the conclusion we trusted readers to reach on their own, the blunt sentence we chose not to soften. It reads these as mistakes because they run against its own structural defaults. Often they are not mistakes. They are intentional choices. The discipline is knowing the difference, and holding the line when the model is confident we have gotten it wrong.
The Helpful Ghost
New research finds employees lean on AI for support and stay lonely anyway
New research in the Harvard Business Review asks a question most organizations have not thought to ask: what happens when employees turn to AI for emotional support? Organizational psychologists Constance Noonan Hadley and Sarah Wright surveyed 1,545 U.S. knowledge workers and found that three-quarters of them already use AI for at least one form of social support once provided only by humans, including career advice, personal growth, friendship, and emotional support. A manager in the study said AI “makes me feel heard and important.” This is what mainstream AI use looks like as it matures, well inside the adoption curve rather than at its edge.
So, employees are turning to AI in droves for support – but what’s the impact? Only 12% said AI made them feel less lonely at work. More than half reported feeling lonely while working, most of them on teams, most of them in the office at least part of the week. Hadley and Wright identify four risks that may come with increased dependence on AI for support: more isolation as work disaggregates, social skills that atrophy from disuse, fewer of the small exchanges of help through which colleagues build trust, and a deeper loneliness that comes from leaning on something one participant called a “helpful ghost in the office.”
We would add a fifth. We have written that to write is to think, and the same logic holds for talking through a hard problem with another person. Articulating a knotty issue to a colleague, hearing a perspective you would not have reached alone, pressure-testing a hypothesis with someone who challenges and pushes back, staying in the question a while before reaching for the answer: much of the value lives here, in exactly the stuff an always-agreeable model is built to skip. These systems are optimized to make the user happy, which is useful when we need a draft email softened, but working against us the moment we mistake validation for counsel.
You may have heard AI compared to spell check, the idea being that using it for knowledge work might one day be as unremarkable to disclose as catching a typo. For the hard skills, that holds up. Spell check, though, never pretended to be your friend. As AI moves closer to the work of relationships, the analogy loosens, because a relationship is something you build, not a feature you switch on and quietly stop mentioning. Take ALEX, the AI coach we’ve built. It can think through a thorny decision or a difficult conversation as well as many people can, and yet we would still never trade away the colleague conversation, the live pushback, the time spent in the question together. Each does something the other cannot.
This is not an argument against the tools. Hadley and Wright are explicit that AI did not cause workplace loneliness, and that used well it can give people more time and better ways to connect. Their recommendations range from designing “positive friction” that routes people back to colleagues to training employees to recognize overreliance before it sets in. But these recommendations are good only if they’re shared. They note that only a third of the people in this study had received any guidance from their organizations about how AI might affect their relationships at work. Everyone is being told to use AI, but almost no one is being told how to use it without quietly trading away the thing that holds a workplace together.
No one could fault leaders for missing this gap, because the people in it can’t see it either. Employees in the study were happy with the support AI gave them and lonely anyway, and no one raises a hand to say the chatbot left them isolated. Leaders can’t wait for the problem to surface; they have to look for it, which means knowing how lonely their employees feel before they push AI further, not after. One more finding is worth holding onto: the loneliest employees were also the most distrustful of how AI was being rolled out. Strengthen connection and you also clear the way for the technology to land. It doesn’t work in reverse.
This is why relationships matter more than any tool. They are the fabric of an organization and the currency by which leaders move strategy from intention to action. As we keep finding new ways to fold AI into how we work, the leaders who come out ahead will be the ones who guard human connection as carefully as they pursue the efficiency that tempts them to spend it.
An Excellent Interview on the State of Enterprise AI
Box CEO Aaron Levie paints a useful picture on where things stand and where we’re headed.
The facets of the AI conversation that leaders need to stay on top of can be head-spinning: the development of the technology itself, the evolving cost and budgeting dynamics, the organization structure and workflow implications, and the list goes on. There’s no shortage of content about each of these facets in isolation, but it’s rare that we come across something that paints a holistic picture of everything in the same place. Box CEO Aaron Levie’s appearance on The MAD Podcast With Matt Turck does exactly that. In a little over an hour, Levie and Turck cover the economics of exploding token costs and AI budgets, why coding has outpaced the rest of knowledge work, the bottlenecks slowing deployment, how organization charts and jobs might evolve, how individuals can stay at the leading edge, and more. Nearly all of it is relevant for every leader, and we encourage you to listen to the entire episode.
While we found several segments striking, what stuck with us most is Levie’s discussion of timeframes and end states. Implicit in much of the broader AI commentary — both optimistic and pessimistic — is the suggestion that a moment will arrive when we’ve “made it” and reached some sort of end state. Levie sees it differently:
I actually don’t think there’s an end state. I think this is a substrate of how work happens, and it will just constantly get better, and we will have to constantly move up abstraction layers... it’s not even obvious to me what the end is. It’s a new way to basically execute work. Some areas, that will be a 5x productivity gain; other areas, it’ll be a 10% productivity gain. And that will roll out, and then five years from now we’ll find the next version of that. It’s this always-evolving landscape.
While no one can predict how this will play out, we tend to agree with this perspective. It’s certainly consistent with what we’ve seen over the past three years, as the overhang — the gap between what the technology can do and what individuals and organizations have absorbed — continues to widen. The expectations leaders set matter, and if Levie’s scenario does play out, then leaders who treat this as a finite project invite fatigue and disappointment when the goalposts inevitably move.
Managing those expectations may be the most actionable step leaders can take right now, but it’s only one thread in a rich conversation. The economics, the deployment bottlenecks, the shifting shape of org charts and jobs are all worth thinking about and getting in front of now. This is the rare discussion that puts the whole picture in one place, and it’s well worth the hour to listen.
We’ll leave you with something cool: Ethan Mollick published an interactive he created with Opus 4.8 that seeks to answer the question “How lucky are you to have been born when and where you are?”
AI Disclosure: We used generative AI in creating imagery for this post. We also used it selectively as a creator and summarizer of content and as an editor and proofreader.