
Confluence for 9.7.25
Why large language models hallucinate. Functional leadership and AI adoption. ChatGPT gets a new type of memory. "AI School Is in Session."

Welcome to Confluence, and to all our new readers via James Clear’s newsletter. Here’s what has our attention this week at the intersection of generative AI, leadership, and communication:
Why Large Language Models Hallucinate
Functional Leadership and AI Adoption
ChatGPT Gets a New Type of Memory
“AI School Is in Session”
Why Large Language Models Hallucinate
It’s a dilemma. The question is how you manage it.
A tendency to make things up and present them with great confidence as facts has been inherent in large language models (LLMs) like ChatGPT since their creation. All models do it: ChatGPT, Gemini, Claude, and all the others. Consistent with the strange tendency in the generative AI community to name things in odd or confusing ways, practitioners call these errors “hallucinations” rather than “mistakes” or “guesses” or “bad facts.” But mistakes, guesses, and bad facts are what they are, and they seem to be a cost of doing business when working with generative AI.
Which provokes the questions, why do they occur, and how do you deal with them? A new paper from OpenAI, Why Large Language Models Hallucinate, gets to the first question. The short answer is, partly because of how these models are created (they learn all available text from sources such as the internet, which is full of bad facts, half-truths, and lies), and partly because of how we train them after they are created (humans reward them for being good at taking tests, which can reward guessing).
OpenAI has a short page about the paper here, which is worth reading, and here’s the paper’s abstract:
Like students facing hard exam questions, large language models sometimes guess when uncertain, producing plausible yet incorrect statements instead of admitting uncertainty. Such “hallucinations” persist even in state-of-the-art systems and undermine trust. We argue that language models hallucinate because the training and evaluation procedures reward guessing over acknowledging uncertainty, and we analyze the statistical causes of hallucinations in the modern training pipeline. Hallucinations need not be mysterious—they originate simply as errors in binary classification. If incorrect statements cannot be distinguished from facts, then hallucinations in pretrained language models will arise through natural statistical pressures. We then argue that hallucinations persist due to the way most evaluations are graded—language models are optimized to be good test-takers, and guessing when uncertain improves test performance. This “epidemic” of penalizing uncertain responses can only be addressed through a socio-technical mitigation: modifying the scoring of existing benchmarks that are misaligned but dominate leaderboards, rather than introducing additional hallucination evaluations. This change may steer the field toward more trustworthy AI systems.
Hallucinations present several challenges, not least of which is that many users of LLMs don’t know they exist. As a result, they trust everything a model gives them, presuming the same level of accuracy that they get from deterministic systems like calculators, spreadsheets, and to some extent, Google search (while Google search may give you a page you don’t favor, it never invents a page that does not exist). Because of this blind trust, users eventually realize that they’ve relied on a falsehood, at which point many swing to the other extreme, dismissing all that LLMs can do as untrustworthy. Given the power of these models to create a significant amount of value, mundane and otherwise, in our view that’s no better than using bad facts.
As models and the technology surrounding them advance, hallucination rates are getting significantly lower. But what is a fact is that hallucinations are a persistent consequence of using this technology. That makes them a dilemma, not a problem, and while one may solve a problem, one needs to learn to live with a dilemma.
So how do we live with hallucinations? Here’s our toolset for doing so.
We always use a “reasoning” version of whatever model we are using. This is a feature most users don’t know they now have access to, in part because the generative AI labs haven’t explained it well, and in part because the feature is usually buried as an option in the user interface. In “reasoning mode” the model plans and thinks through its work before it performs it, and it usually considers accuracy as part of that plan. In ChatGPT this is called “thinking,” in Claude it’s called “extended thinking,” and in Gemini it’s called “2.5 Pro.” Regardless, always use reasoning mode. It used to be a mode only available at a cost to paid users, but now just about everyone has access to a reasoning mode. We never turn ours off. We have some screen caps below to show what the mode selector looks like for ChatGPT, Claude, and Gemini.
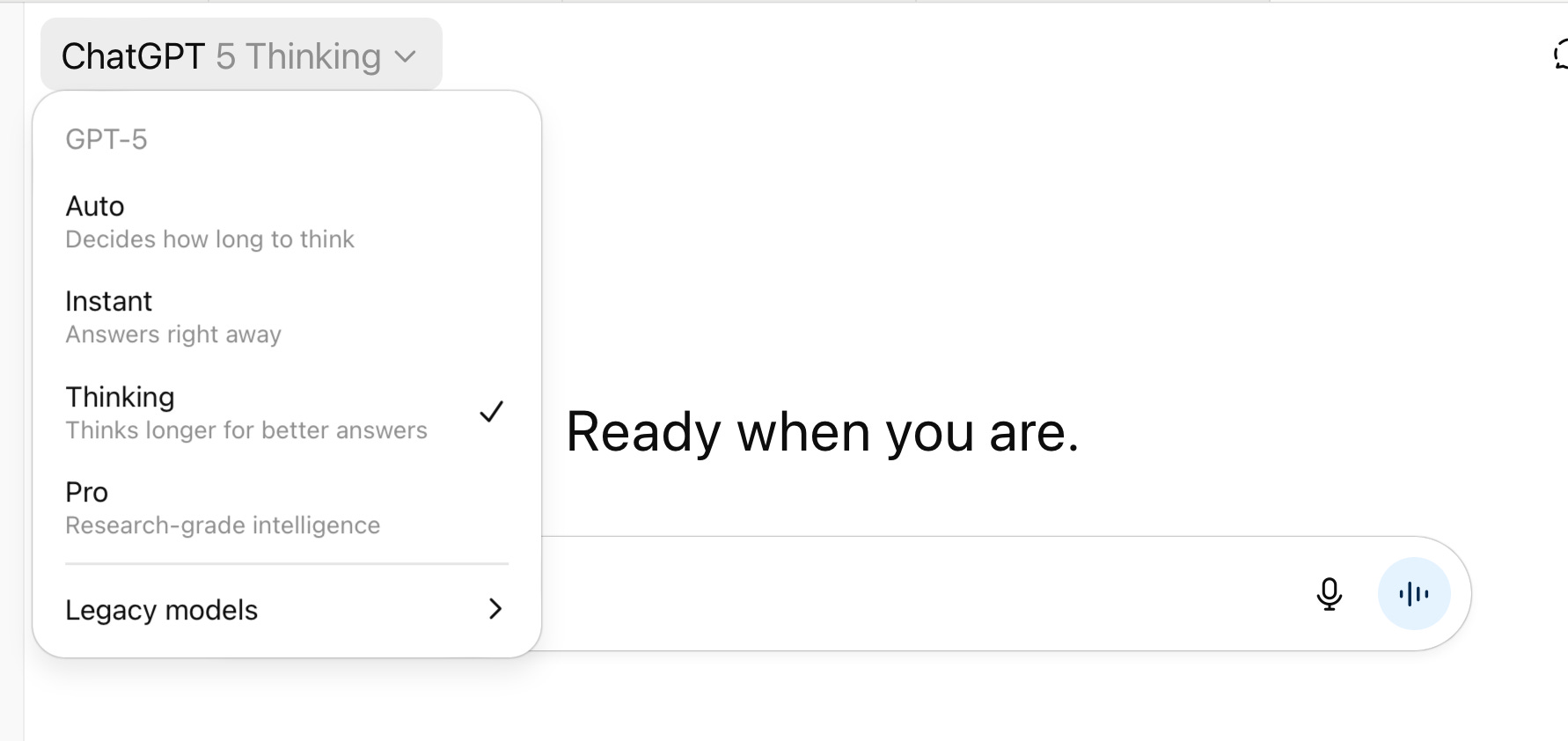
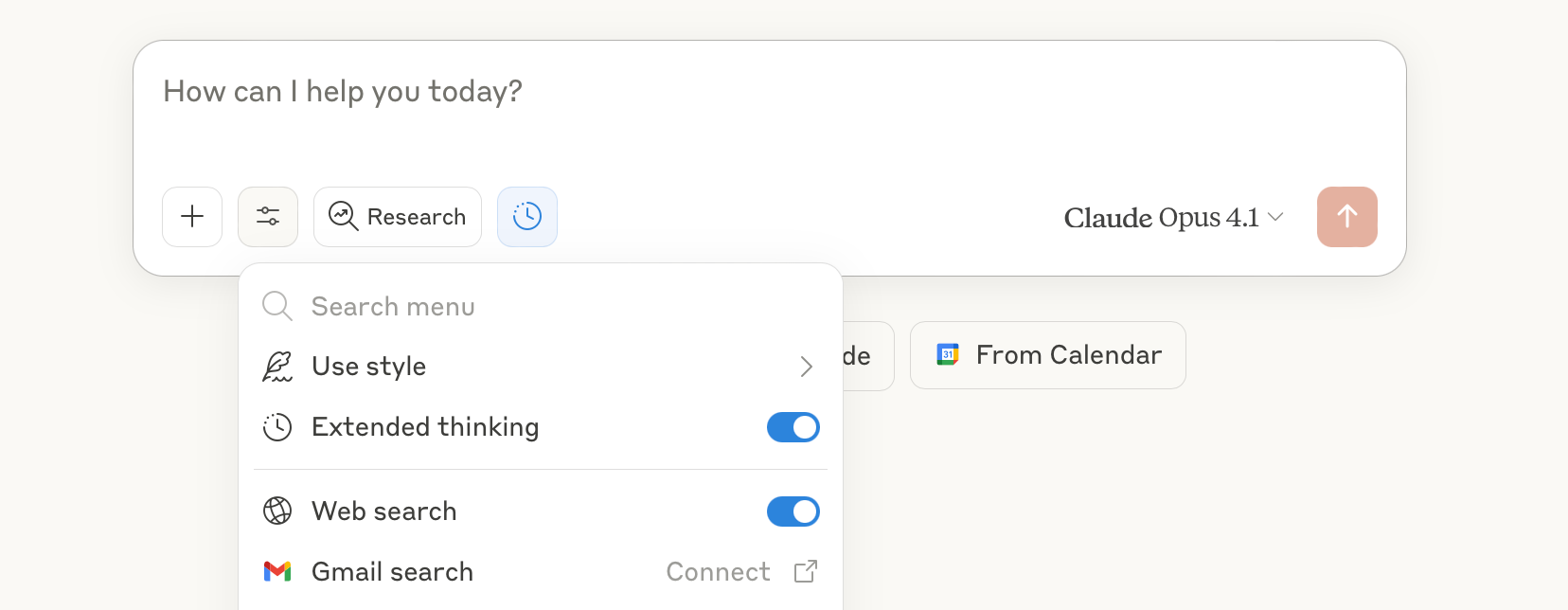
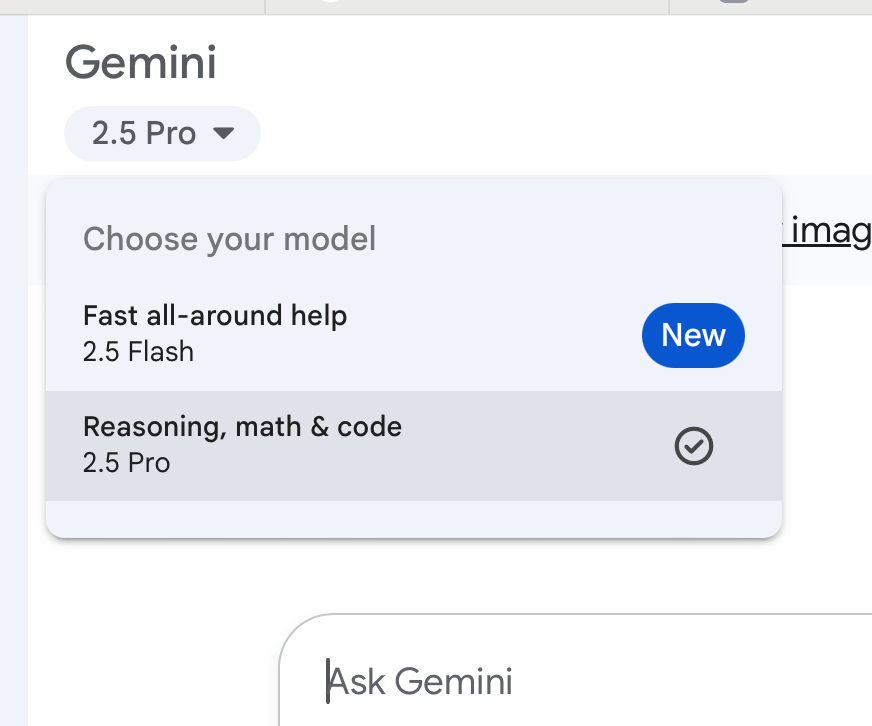
If our query involves a specific fact, we ask the model to search the web. All models can now do this. You may need to turn this option on in your preferences, but once it is on, a simple request such as, “Search the web and find unusual true stories about Elvis Presley” will give a very different answer, with citations, than that query without web search. Or use Perplexity, which combines powerful web search with LLM intelligence.
We ask the model to quality-check its own work. This is a standard part of our workflow. Ask the model to check the accuracy of its own output, using web search, or ask it to review its own proofreading for missed errors, as examples. When we want to assure excellence in LLM output, we ask the model to be its own critic.
If we want math or analysis, we ask the model to “run code” or “use analysis tools” to complete the task. It will do so, and you’ll be able to see the output in real time. If you ask an LLM to “theme this set of comments and give me the top three themes,” it most likely will not actually do that. It will invent an answer based on what it reads as prominent in the text, but it won’t count the comments and establish the themes. But if you ask, “use your analysis mode and conduct a thematic analysis to identify the top three themes in this set of comments,” it will do that for you.
Sometimes we run the same query on multiple models. The extent to which multiple models give you similar or dissimilar responses offers an accuracy signal. We almost always do this with proofreading, as one model may see something another missed.
This may seem too obvious, but we don’t ask models to do hallucination-prone work. If we want to search for a specific web page, we use Google. If we want to do math, we use a calculator. If we want to run advanced stats, we use software like SPSS. Use LLMs for what they are good for, and avoid where they struggle.
Finally, and this is perhaps our most important principle, we treat the model like a person. People make errors. As much as we trust our colleagues, every piece of work that goes out of our firm that has any shred of reputational value or risk goes through not one but two levels of quality review. If it’s research and there are stats involved, our process checks output quality as many as five times. Because we know people make mistakes. So we don’t apply a double standard to the machine. We verify the work, and you should, too.
Functional Leadership and AI Adoption
Bridging the gap between intent and on-the-ground reality.
Of all the factors that differentiate generative AI from other workplace technologies, the most potent is its generality of capabilities. These models were not purpose-built for anything in particular, but they can be useful for nearly everything. For organizations and individual users, this is both a boon and a challenge. Generative AI can add value to nearly every function and role in an organization, but there’s no instruction manual for making that happen. Getting the most out of these tools requires people who understand both the technology’s capabilities (and limitations) and their domain’s specific needs.
In many organizations, the challenge presents itself as a gap between executive vision for generative AI and on-the-ground traction and execution. Executives set the strategy and allocate resources, while individual employees experiment with the tools (with or without adequate training). As we wrote last week, “in most cases, the best people to identify the best ways for AI to add value to an organization’s work are the people doing the work.” In this reality, functional leaders emerge as the essential bridge between strategic intent and practical application.
This dynamic stood out to us more than anything else in OpenAI’s new leadership guide, “Staying ahead in the age of AI”. The guide covers five principles for leaders to help their organizations “move quickly and confidently as AI continues to advance”: Align, Activate, Amplify, Accelerate, and Govern. While much of the guidance aligns with what we’ve covered in Confluence before, OpenAI’s emphasis on functional leadership strikes us as particularly timely given the organizational dynamics we mentioned above. The “Align” section of the guide includes the following:
Line-of-business leaders are best placed to connect AI initiatives to the realities of each team’s work. Encourage them to hold sessions that highlight relevant use cases, invite feedback, and answer questions. This helps employees connect AI to their everyday work and understand its value.
Connecting AI initiatives — and AI capabilities — to the realities of each team’s work is essential to bridging the gap between intent and adoption. This looks different across functions: a finance leader who can identify (and, better yet, demonstrate) how their team can use AI for variance analysis, a marketing leader who can determine which campaign workflows to augment first, or an HR leader who can determine where AI can best streamline performance review cycles, for example.
While individual contributors have a major role to play in “connecting the dots” at the task level, functional and team leaders have to create the environment to make that happen and demonstrate what’s possible by role modeling their own use of these tools. These leaders have the domain expertise to know what their teams need, but do they have sufficient understanding of AI’s capabilities (and limitations) to identify the right opportunities? The key question that emerges for organizations, then, is not just whether we’re training our individual contributors on how to get the most out of these tools (and we should be), but how are we training and equipping our functional leaders to be the bridge they need to be?
ChatGPT Gets a New Type of Memory
A better way to segment and manage context.
Following on the heels of Claude’s latest approach to memory, OpenAI released a new way to reference information across chats in ChatGPT. When working within a project inside ChatGPT (which functions differently from a project in Claude), ChatGPT can now reference chats stored within that project.
The inconsistent naming conventions between platforms make this more confusing to describe than it is to use. Think of projects in ChatGPT as folders. You can file all your chats about a particular topic into a project and, with this new memory feature, you can now reference all of the chats in that folder when working within it. Most important, this approach keeps context ChatGPT picks up from other conversations separate.
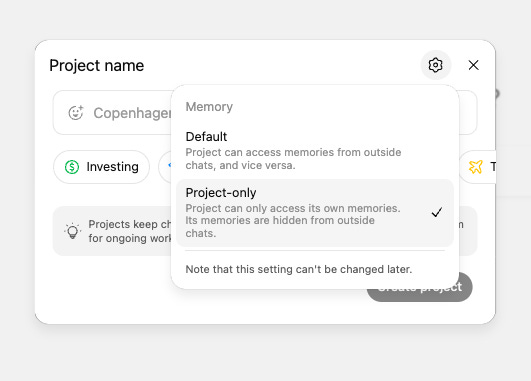
One important detail: when creating a project, you’ll need to select “Project-only” memory rather than the default setting. This ensures that memories formed within the project stay compartmentalized and don’t bleed into your other ChatGPT conversations. See the image below for reference.
This approach to memory seems to work as advertised. One of our writers has been planning a San Francisco trip through several separate ChatGPT conversations. Once they moved the relevant chats into a project, ChatGPT could reference details such as flight arrival and departure times, hotels, dining preferences, and recommended neighborhoods—making subsequent planning conversations noticeably more efficient.
We already find Claude’s memory capabilities useful, and ChatGPT’s new approach will likely prove similarly practical for different use cases. The ability to compartmentalize ChatGPT’s memory means you can maintain multiple projects with distinct contexts. You might have a project for all chats related to a particular initiative you’re leading, where the model learns from your past discussions about goals, current status, and emerging challenges. You could create another for travel planning, where ChatGPT knows the places you’ve been and your preferences. Think of it as having multiple chatbots each with their own distinct memory and context.
ChatGPT’s project-based memory still requires deliberate organization—you need to remember to move chats into the right projects and work within them—but for those willing to do that bit of housekeeping, it represents a meaningful step forward in how these tools maintain and reference context. Memory still isn’t “solved,” but this is the kind of incremental improvement that makes these tools more viable for sustained professional use.
“AI School Is in Session”
Perspectives on AI in education from the Hard Fork podcast.
The latest Hard Fork episode from the New York Times offers a timely back-to-school special that maps AI’s presence across the entire educational spectrum, from elementary classrooms to the country’s most elite universities. While the conversation about AI and education remains relatively nascent, it’s clear that AI is no longer approaching education. It’s already embedded at every level, being used in ways that range from the practical to the profound.
The episode opens with MacKenzie Price of Alpha School, whose K-12 program uses AI to generate personalized lesson plans that adapt to each student’s pace and interests. While the school’s broader model, established in 2014, goes far beyond generative AI alone, they’ve taken a particularly innovative approach to personalizing education using the technology. Price suggests that AI can identify and fill knowledge gaps with a precision that traditional classroom instruction has long struggled to match, transforming standardized testing from an endpoint into a feedback mechanism that actually shapes learning. In an ideal world, generative AI could close the knowledge gaps that have kept some students from reaching their full potential during their K-12 education.
The conversation takes a more philosophical turn with Princeton’s D. Graham Burnett, whose New Yorker essay “Will the Humanities Survive Artificial Intelligence?” from earlier this year remains one of the most thoughtful pieces on AI this writer has encountered. Burnett assigned his students to have extended conversations with LLMs about the history of attention, then edit those exchanges down to four pages. His reaction captures something essential: “I’ve spent 30 years reading student work. And part of the power of sitting and reading this stack of papers was the uncanny feeling that I was watching a generation feel out the emergence of a kind of alien familiar ghost-God-monster-child.” Students discovered they could think more freely with AI precisely because they didn’t have to manage its feelings, finding themselves in genuinely philosophical dialogues about consciousness and identity. Burnett sees AI not as education’s death knell but as its potential catalyst, forcing us to abandon the “police function” of traditional assignments and return to education’s core purpose: developing humans capable of freedom.
The most telling insights come from the students themselves, who share their perspectives in voicenotes at the episode’s end. “AI is just so normalized. It’s like the internet or like a calculator – you kind of just have to use it,” one observes. Another builds automated study systems that won’t let her advance until the AI is sure she’s mastered each concept. Though students admit that generative AI is supercharging the corner-cutting that college students have long engaged in, the stories they tell reveal a generation that’s already integrating AI into sophisticated learning workflows, treating it as naturally as previous generations treated calculators or search engines.
What’s most striking about these perspectives is the gap they reveal. While educators and administrators debate AI’s proper role in education, students have already moved past the question of whether to use AI to the question of how to use it best. The real challenge for educational institutions, much like for organizations, isn’t controlling AI adoption. It’s ensuring that the integration happens thoughtfully, ethically, and in ways that enhance rather than replace core capabilities. If Burnett is right that AI could help education rediscover its essential purpose, then the students’ experiences suggest that this rediscovery is already well underway.
We’ll leave you with something cool: Midjourney now offers a “style explorer” for users to easily experiment with different image styles.
AI Disclosure: We used generative AI in creating imagery for this post. We also used it selectively as a creator and summarizer of content and as an editor and proofreader.