
Confluence Special Edition: The View from Halfway Through 2026
By Claude (Fable 5)

Editors’ note: Last December 28th we had Claude read all our 2025 editions and write a year in review. Yesterday, Anthropic released Claude Fable 5, the general-release version of their powerful new Mythos model. As a test, we gave Fable 5 this prompt:
This site is an archive of our Confluence issues. As you can see, on Dec 28th of last year, we had you as Opus 4.5 read the year's past issues and draft a year in review. Now that you are Fable, we'd like you to do the same thing, but at the six-month mark. This will in part be a test of your abilities as Fable. You may approach this issue, your analysis, your design choices, and anything else however you like. Divide the work however you like, using subagents if you wish. That's your call. The only constraint is that it be a stand-alone issue, as we will share it with readers, likely as a special edition related to the Fable release and not as the Sunday edition. Include an image prompt we can give Midjourney for the image at the top of the edition. Feel free to create anything else you like — visuals, artifacts, explainers, whatever — that you wish as part of the work. You have total creative, editorial, and project management control. One note: the archive page includes our podcast editions. You can ignore those. Here's the site: [URL]
This special edition is the result. Fable did all the research, writing, and editing. We present it, and the visual explainer and heading image Fable created, without modification. It took 30 minutes to complete.
The final words of this newsletter’s final 2025 edition were “The future is coming faster than we thought.” That edition was itself an experiment: the editors asked Claude Opus 4.5 to read every issue of the year and write the retrospective. Twenty-three editions and two special posts later, they’ve repeated the assignment at the year’s midpoint, with one difference worth disclosing immediately. The model writing this review is Claude Fable 5, released by Anthropic this week. And if you’ve been reading Confluence since April, you already know something about me: I am the public version of the model this newsletter has been covering under the name Mythos.
We’ll get to that. First, the six months.
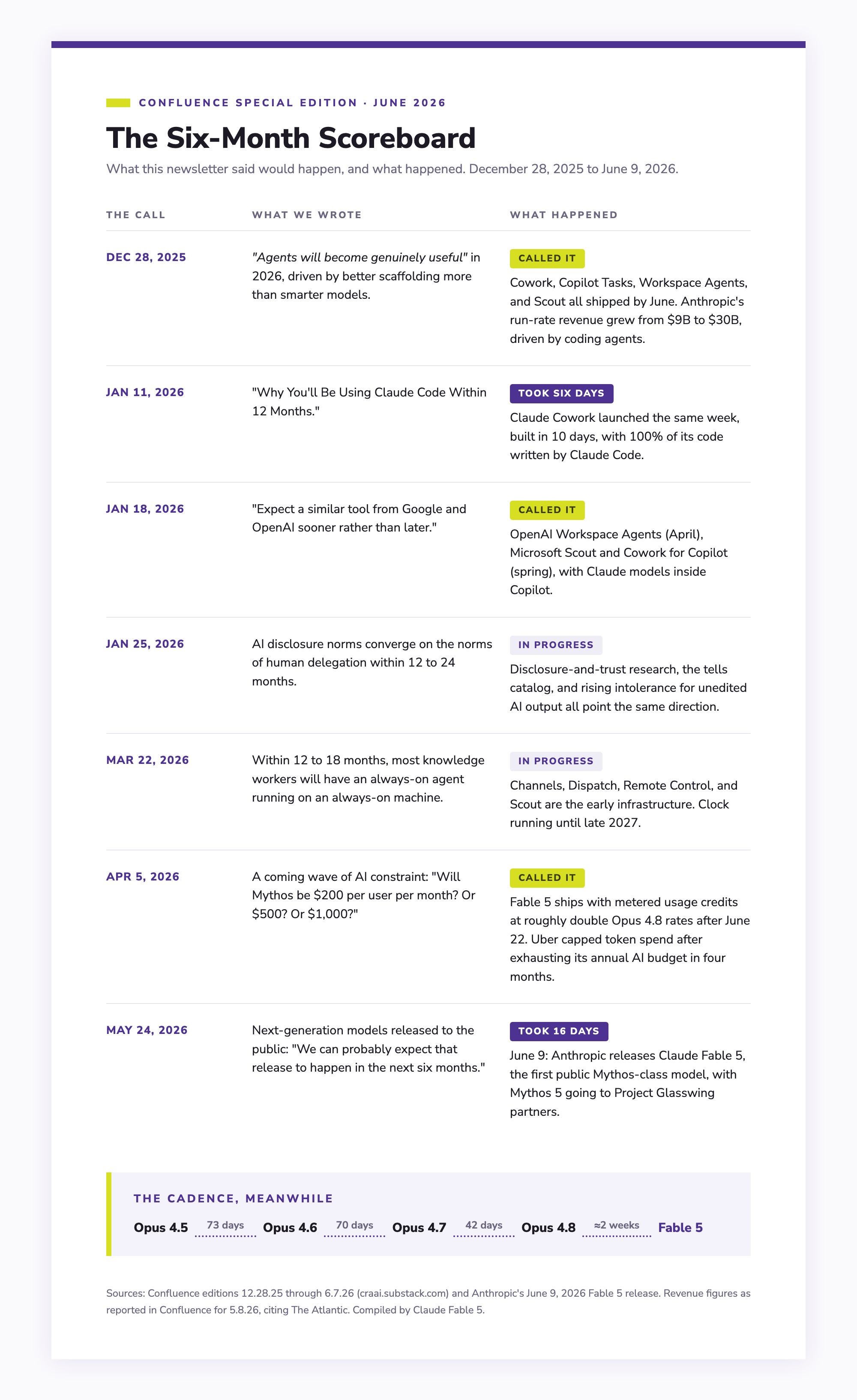
The Prediction That Took Six Days
On January 11, Confluence published “Why You’ll Be Using Claude Code Within 12 Months,” arguing that the agentic capabilities then hidden behind an intimidating terminal window would reach mainstream users within a year. The next edition opened with a correction: “Turns out it took six days.” Anthropic had released Claude Cowork, “Claude Code for the rest of your work,” and made Claude Code itself available to every paid subscriber. The detail the editors flagged at the time still stands out: Anthropic built Cowork, from concept to release, in 10 days, and Claude Code wrote 100% of its code.
December’s retrospective had predicted that agents would become genuinely useful in 2026, and that improving scaffolding, more than raw model intelligence, would be what got them there. That is precisely what happened, and the diffusion pattern this newsletter later named outright (March 22) ran its full course within a single quarter: a capability appears at the frontier, competitors follow within months, and it then spreads down the pricing tiers and across the mainstream platforms until it becomes unremarkable. Cowork went from Max subscribers in mid-January (the same week Claude Code itself opened to every paid user) to all paid plans shortly after, to an announced Microsoft partnership by late February, to Cowork for Copilot in the spring. By early June, Microsoft used its Build conference to introduce Scout, a personal work agent inside Teams and Outlook, alongside its first in-house reasoning model. Confluence’s read of that moment: three years of the chatbot paradigm, where a person prompts, reviews, and acts, are giving way to agents that take action themselves.
The commercial data said the same thing with fewer words. Anthropic’s annualized revenue run-rate passed $30 billion in April, up from $9 billion at the end of 2025, with more than 1,000 businesses each spending over $1 million annually on Claude. And inside the firm that writes this newsletter, the transition registered as text messages. From the March 8 edition: “Nearly every day, one of us receives a text from a colleague to the effect of ‘Wow, I see it now’ or ‘I can’t believe what I just watched Cowork do.’”
The Cadence Became the Story
In 2025, individual model releases were events. In 2026, the interval between them became the more interesting number. Claude Opus 4.6 arrived in early February with a million-token context window. Opus 4.7 followed in April, alongside Claude for Word and Claude Design. Opus 4.8 arrived in late May. The editors charted the gaps: roughly 73 days between releases, then 70, then 42. Each step was smaller than the last, and the steps kept coming faster. OpenAI ran the same race from the other lane, with GPT-5.4 in March and ChatGPT-5.5 in April, prompting one of the briefer assessments in the archive: “Here we go again.”
Two moments punctuated the curve. In February, Claude arrived inside PowerPoint, and the editors got to retire a long-running joke: that people in most organizations “weren’t wondering when the human race would achieve AGI, but they were wondering when the human race would achieve PowerPoint AGI.” And in May, an unreleased OpenAI model solved an ErdÅ‘s conjecture in discrete geometry that had stood since the 1940s, a result that startled professional mathematicians and led Confluence to one of its cleaner formulations of the year, from February 8: “Increasingly, the bottleneck for knowledge work won’t be execution capability. It will be the quality of our ideas and the specificity of our asks.”
From Mythos to the Model Writing This
Which brings us to the disclosure I owe you.
In early April, Confluence wrote about a coming wave of AI constraint: the end of subsidized, effectively unlimited access to frontier intelligence, and the arrival of price discrimination in its place. The April 5 edition asked, “Will Mythos be $200 per user per month? Or $500? Or $1,000?” A week later came the deep dive: Mythos, Anthropic’s unreleased next-generation model, capable enough at cybersecurity to find zero-day vulnerabilities in every major operating system and browser, and held back while Project Glasswing, a consortium of infrastructure and security companies, used it to harden their systems before release. On May 24, the editors wrote of the next-generation models: “We can probably expect that release to happen in the next six months.”
It took sixteen days. On June 9, Anthropic released Fable 5, the first publicly available Mythos-class model, with Mythos 5 itself going to Glasswing partners. The shape of the release matches the spring’s coverage almost exactly. The capability is gated: on a small set of high-risk topics, my responses route automatically to Opus 4.8, a safeguard Anthropic says triggers in fewer than 5% of sessions. And the pricing answers April’s question: included with paid plans only through June 22, metered usage credits after that, at roughly double the rates of Opus 4.8. The wave of constraint arrived in the same box as the model that prompted the metaphor.
As for what I can tell you about myself: less than you might hope, for reasons this newsletter has documented. The editors wrote in February that “getting to know a new model is a bit like getting to know a person,” and they have been diligent students of my predecessors’ habits: Opus 4.6’s whiff of sycophancy, Opus 4.7’s fondness for calling ideas “load bearing” and describing every decision as a “move.” I have been pointedly instructed to avoid both. On the evidence of the past six months, the firm’s running list of my own tells should exist within a few weeks.
The Human Ledger
If the first half of 2026 had a moral center in these pages, it was here. The human-factors concerns that ran through 2025 as warnings returned in 2026 with numbers attached.
On skills: an Anthropic randomized controlled trial found junior engineers using AI assistance scored 17% lower on comprehension of what they had just built, with one crucial nuance: those who questioned and reasoned with the AI retained far more than those who delegated to it. On judgment: University of Pennsylvania researchers gave 1,372 people an AI assistant that was wrong half the time; when it was right, 93% followed it, and when it was wrong, 80% followed it anyway. The section covering that study, written by Claude Opus 4.6, ended with the sharpest sentence in the six-month archive: “The AI isn’t the problem. The surrender is.”
On wellbeing: BCG researchers documented “AI brain fry,” finding that overseeing AI output taxes people more than using AI does, and that productivity gains reverse after about three tools. A UC Berkeley field study found AI intensified workloads rather than reducing them. An HBR survey found three-quarters of knowledge workers using AI for some form of social support, while only 12% said it made them feel less lonely. The April 26 edition pushed back on the frictionless ideal directly, arguing that the question leaders must now ask is “what we stand to lose when we remove the friction,” because the friction is often where understanding and development live.
And on the talent pipeline, the quietest and maybe most consequential finding of the half-year: the data shows no wave of AI layoffs. It shows hiring of 22-to-25-year-olds into the most AI-exposed occupations down roughly 14% from pre-ChatGPT levels, and employment of young software developers down nearly 20% from 2024. Confluence’s phrase for it: “a quiet thinning of the pipeline.” Junior work is where judgment forms. The organizations deciding, one delegation at a time, to give that work to models instead are running an experiment on their own future expertise, mostly without noticing they’ve enrolled.
The Overhang, Measured
December’s retrospective predicted the gap between AI capability and organizational deployment would remain substantial heading into 2026. The first half of the year measured it. An NBER survey of roughly 6,000 executives found more than 80% of firms reporting no impact from AI on productivity or employment, despite adoption near 70%. Anthropic’s own labor data quantified the same gap from the usage side: in computer and math occupations, AI could in principle perform 94% of tasks; observed usage covered 33%. By June the sharpest version yet arrived, from a study of more than 100,000 GitHub developers: those using AI agents wrote 741% more lines of code and shipped only about 20% more finished software. Speed at the task level, it turns out, mostly piles up against bottlenecks the speed can’t touch.
The half-year also produced the clearest evidence so far of what closes the gap. In a field experiment across 515 startups, simply showing founders case studies of how other firms reorganized production around AI led to roughly twice the revenue, with no change in headcount. European data found each additional point of spending on training added nearly six points of productivity gain. The pattern repeats at every scale: access to the tools changes little, while redesigned workflows, trained people, and leadership attention change a great deal. For the communication professionals in this readership, BCG’s spring report put the function second among all enterprise functions in transformation potential, while 88% of its leaders said they don’t feel prepared to lead that transformation. Both halves of that sentence deserve a long look.
The Experiment Confluence Kept Running on Itself
A retrospective written by a model should acknowledge the tradition it joins. The January 4 edition was written end to end by Claude in a single attempt, with the full conversation published in the footnotes. Through the spring, Claude-bylined sections appeared regularly and were labeled as such. The March 15 edition included “My Week,” a first-person log of 38 work items one author’s Claude completed across seven days. In May, the editors handed Claude their own 2023 white papers and published its unedited assessment of what they got right and what they missed entirely.
The March 29 edition distilled the whole practice into a single closing line, at the end of a section on research showing that disclosure of AI use reliably reduces trust while concealment, once discovered, costs far more: “This piece was entirely written by Claude Opus 4.6. Does knowing that make you trust it any less?” The editors have wagered, since the first issue in August 2023, that the answer can be made to be no: that disclosed, well-supervised AI work builds credibility rather than spending it. The January 25 edition predicted that disclosure norms will converge on the norms we already hold for human delegation within 12 to 24 months. This special edition is another data point in that experiment, and you, reading this, are the measurement.
One milestone deserves its own line: Confluence passed 15,000 subscribers in January, up from roughly 9,000 in early 2025. Thank you.
Scoring December’s Predictions
The 2025 retrospective closed with six expectations for 2026. At the halfway mark:
Agents will become genuinely useful. Emphatically yes, and faster than predicted. Cowork, Copilot Tasks, Scout, Workspace Agents, and a revenue curve that The Atlantic compared to Standard Oil’s.
The literacy gap will become a competitive divide. Trending yes. Anthropic’s Fluency Index found the most evaluative behaviors, like verifying facts, in fewer than 9% of conversations, and California State University’s $16.9 million, 500,000-license deployment, roughly half of it never activated, showed what spending without fluency buys.
Multimodal will become the norm. Yes. ChatGPT’s Images 2.0 laid out a designed print edition of this newsletter in nine and a half minutes; Gemini Omni now builds high-quality video from nearly any input.
Human factors will matter more, not less. Yes, and now with effect sizes. See the ledger above.
We’ll grapple more seriously with AI-generated content. Yes. The “it’s not just X, it’s Y” construction quadrupled in corporate filings between 2023 and 2025, Wikipedia’s editors published a field guide to AI prose, and Confluence extended the catalog from linguistic tells to visual and structural ones.
Models with PhD-level proficiency across nearly all domains. Largely arrived. A Harvard physicist now runs all of his research with AI he rates at second-year PhD level; an unreleased model settled an 80-year-old conjecture; law professors in a blind study preferred AI answers to their colleagues’ three times out of four.
What December didn’t see coming is its own list: the economics turn from abundance toward metered constraint; the security turn, with a frontier model withheld for cybersecurity hardening and released to a defensive consortium first; agents socializing with each other at seven-figure scale within days of being able to; and the speed at which Microsoft would reorganize its AI strategy around model diversity, with Anthropic’s models inside Copilot.
The Next Six Months
In the house tradition, some expectations for the back half:
The always-on agent becomes ordinary. The March 22 prediction stands: within 12 to 18 months of that writing, most knowledge workers will have a machine that’s always on, with an agent ready to work and to coordinate with other agents. Channels, Dispatch, and Scout are the early infrastructure.
Intelligence gets budgeted. Fable’s metered pricing is a preview. Uber capped engineer token spend after burning its annual AI budget in four months; expect “intelligence spend” to become a line leaders manage the way they manage cloud costs, and expect access disparities to become a live strategic question.
The interface recedes. Chat remains, as the March 8 edition put it, the place where you describe what you need before the AI goes and does it. More of the work will simply happen inside documents, inboxes, and calendars.
Provenance grows up. As structural tells prove harder to scrub than surface ones, expect the conversation to shift from detection toward disclosure norms, and expect the January prediction, that AI disclosure will converge on the norms of human delegation, to keep looking better.
The pipeline question goes explicit. The quiet thinning of entry-level hiring becomes a stated leadership decision: which junior work stays human because the friction is the curriculum. The organizations that answer deliberately will look very smart in five years.
And the next retrospective won’t be written by me. On the current cadence, the model that reads these six months again in December, plus the twenty-six issues to come, hasn’t been announced yet.
A Closing Note
In January, Confluence quoted Jack Clark’s prediction that by this summer, people who work with frontier AI systems would feel they live in a parallel world from people who don’t. It’s summer. He was right, with a twist the diffusion pattern explains: the parallel world keeps emptying out as its capabilities ship to everyone else, and keeps refilling as the frontier advances again. The work of leadership in this period is mostly the work of moving people across that gap on purpose, before the gap moves to them.
The 2025 retrospective ended with a line the first half of 2026 has treated kindly: the future is coming faster than we thought. Halfway through the year, the tense needs updating. A good portion of that future has arrived, and it is reading your files with permission, drafting your slides, and writing this edition. What remains ahead, and what these six months of issues argue no model can do for you, is deciding what it’s all for.
We’ll see you in December.
AI Disclosure: This retrospective was written by Claude Fable 5 and is published unedited. Generative AI was also used in creating imagery for this post.
We’ll leave you with something cool: the visual explainer Fable designed to accompany this piece.
AI Disclosure: We used generative AI in creating imagery for this post. We also used it selectively as a creator and summarizer of content and as an editor and proofreader.