


Confluence for 6.15.25
OpenAI releases o3-pro. New research examines firm-level exposure to generative AI. Read the fine print on research about GenAI. Generative AI changes work, but it also changes org charts.

Welcome to Confluence. Here’s what has our attention this week at the intersection of generative AI, leadership, and corporate communication:
OpenAI Releases o3-pro
New Research Examines Firm-Level Exposure to Generative AI
Read the Fine Print on Research About GenAI
Generative AI Changes Work, but It Also Changes Org Charts
OpenAI Releases o3-pro
A reminder that leading reasoning models need ample context.
OpenAI released o3-pro this week, an iteration on the previously released o3. They describe it as a “version of our most intelligent model, o3, designed to think longer and provide the most reliable responses.”
We wrote about o3 shortly after its release, and everything we wrote then remains true about o3-pro. It’s remarkably capable, both in terms of sheer intelligence and its ability to act as an agent. It pushes the boundaries of what’s possible with generative AI and we still find new, creative ways to use it, even as we prefer Claude Opus 4 for much of our day-to-day work. If you haven’t read what we shared then or used o3 or o3-pro, do it. It’s worth your time.
Latent Space, a Substack discussing the more technical side of generative AI, wrote about o3-pro and its capabilities. Their write-up struck us with its description of the difficulties they faced when evaluating o3-pro:
But therein lines [sic] the problem with evaluating o3 pro.
It’s smarter. much smarter.
But in order to see that, you need to give it a lot more context. and I’m running out of context.
There was no simple test or question i could ask it that blew me away.
But then I took a different approach. My co-founder Alexis and I took the the time to assemble a history of all of our past planning meetings at Raindrop, all of our goals, even record voice memos: and then asked o3-pro to come up with a plan.
We were blown away; it spit out the exact kind of concrete plan and analysis I’ve always wanted an LLM to create — complete with target metrics, timelines, what to prioritize, and strict instructions on what to absolutely cut.
The plan o3 gave us was plausible, reasonable; but the plan o3 Pro gave us was specific and rooted enough that it actually changed how we are thinking about our future.
This is hard to capture in an eval.
We experience the same challenge. The frontier models, o3-pro, Claude Opus 4, Gemini 2.5 Pro, possess sufficient capability that the differences are subtle and often emerge only in the most complex use cases and when we provide ample context. We’ve yet to have a moment similar to what’s described above in our own use of o3-pro, but we don’t believe it’s because the model lacks capability.
This is not to say these models can do everything we want them to do. They still have real limitations. You must spend real time with them, task them with real work, and, as Latent Space notes, give them ample context to really understand their capabilities.
The context question will become easier to address over time. In the past we needed to provide this context ourselves. This is less and less the case. We’ve highlighted Claude’s increasing access to your world and ChatGPT now integrates with the full Microsoft Suite (if you have a Team or Enterprise account and your admin allows it). While we still need to provide sufficient context for the task at hand, the models can now search for the information they need without us feeding it to them directly.
As we test newer and more capable models, we should prioritize the models’ need for context. Whether we provide the models the context directly or give them access to existing data through Google Workspace, SharePoint, and other sources, we should ask ourselves “could a colleague perform the task with the same level of context?” If the answer is no, then we must give the models more.
New Research Examines Firm-Level Exposure to Generative AI
More evidence that generative AI is a general purpose technology.
This week, we turn again to Claude as an author, this time to summarize important new research from our friend Daniel Rock and his collaborators. The piece below was authored entirely by Claude, with no human editing other than to insert links to the research papers. As always, the prompt is in the footnotes.1 Given the technical nature of this paper, our prompting was a bit more detailed than usual. One thing to note — the authors use the same exposure data and analysis as the original “GPTs Are GPTs” study to inform this work. The original paper used GPT-4 as a benchmark, a model lagging behind from today’s frontier. Because the original study focused on what LLMs can generally do and not specific model capabilities, we expect these findings to hold even with the latest models.
A new research paper from the American Economic Association extends the influential “GPTs Are GPTs” study to the company level, providing concrete evidence about which firms stand to be most affected by large language models. The researchers, led by Benjamin Labaschin from Workhelix and including OpenAI’s Tyna Eloundou and University of Pennsylvania’s Daniel Rock, analyzed employment data from nearly 8,000 publicly traded companies to understand how LLM exposure varies across organizations.
The study builds on earlier work that evaluated which occupations and tasks could be enhanced by LLMs like GPT-4. By combining these task-level exposure scores with detailed employment data from Revelio Labs, the researchers created firm-level measures of LLM exposure. They found that the median company has about 16% of its tasks exposed to current LLM capabilities (tasks where LLMs can reduce completion time by at least 50% without quality loss). When accounting for potential software integrations, this jumps to 47%, and with full software deployment, reaches 77%.
Two findings stand out. First, companies with more technology workers—software developers, data scientists, and computer programmers—show significantly higher LLM exposure levels. These firms have roughly 10% more exposed tasks than their peers, likely because tech workers both use LLMs more directly and can build the software integrations needed to unlock additional use cases. Second, companies with employees who have AI skills (those listing machine learning, artificial intelligence, or related capabilities on their résumés) cluster in firms with higher overall LLM exposure. The correlation is striking: firms with 0.5 higher average exposure scores have approximately 24 more employees with AI skills.
These patterns matter because they provide mounting evidence that LLMs qualify as general purpose technologies (GPTs)—innovations that transform entire economies rather than specific sectors. GPTs share three characteristics: they improve rapidly over time, they’re pervasive across many uses and industries, and they spawn complementary innovations. The paper’s findings check all three boxes. The pervasiveness is clear from the data: LLM exposure affects the vast majority of firms, with even low-exposure companies having 69% of tasks potentially impacted when software tools are considered. The complementary innovation piece shows up in the gap between current capabilities (E1 tasks) and what’s possible with additional software (E2 tasks)—a 50 percentage point difference that represents massive potential for new tools and applications.
For leaders, this research reinforces several critical points. First, LLM impact will be broad-based rather than concentrated in a few industries or job types. Nearly every organization will need to grapple with these technologies. Second, companies with existing technical talent have a head start—not just because these workers can use LLMs effectively, but because they can build the integrations that multiply LLM value. Third, the gap between current and potential applications suggests we’re still in early days. Organizations that invest in understanding and developing LLM applications now may capture outsized benefits as the complementary innovations emerge. Finally, the general purpose nature of LLMs means their impact will likely accelerate rather than plateau. Like electricity or the internet before them, LLMs appear poised to become infrastructure that enables waves of innovation we can’t yet fully imagine. Leaders who recognize this pattern can position their organizations accordingly, building the capabilities and culture needed to adapt as this technology continues its rapid evolution.
Read the Fine Print on Research About GenAI
A recent paper illustrates that timing and models matter.
While on the topic of LLM research, a colleague recently was helpful to forward this article out of Tulane (headline: New Tulane study finds generative AI can boost employee creativity—but only for strategic thinkers) which describes this soon-to-publish paper in the Journal of Applied Psychology on the relationship between using large language models and creativity. Here’s Claude’s summary of the paper:
Researchers from Tulane University, Renmin University of China, Nanyang Technological University, Rice University, and MIT Sloan conducted a field experiment with 250 employees at a technology consulting firm to examine how generative AI affects workplace creativity. Half the participants received access to ChatGPT for a week while the other half continued working normally. The study measured creativity through both supervisor ratings and external evaluators who assessed novel responses to workplace scenarios. Results showed that employees with AI access demonstrated higher creativity scores and gained more “cognitive job resources” - better access to information and opportunities to alternate between complex and simple tasks.
The effects varied significantly based on individual differences in metacognitive strategies, which involve actively monitoring and regulating one’s thinking processes. Employees with strong metacognitive skills - those who regularly assess task demands, track their problem-solving effectiveness, and adjust their approaches - showed substantial creativity gains from AI access. In contrast, employees with weaker metacognitive strategies experienced no meaningful improvement in creativity despite having the same AI tools available. The study suggests that cognitive job resources mediate the relationship between AI use and creativity, but only for employees who can strategically leverage these tools through deliberate thinking about their own thought processes.
For professionals and organizations, these findings suggest that simply providing AI access may not deliver expected creativity benefits across all employees. Organizations might need to assess workers’ metacognitive abilities before deploying AI tools or invest in training that helps employees develop stronger self-monitoring and strategic thinking skills. The research indicates that the most effective AI adopters are those who can step back, evaluate their work approach, and consciously decide how to integrate AI assistance into their problem-solving process rather than using it passively.
At first blush, this finding would seem significant, especially given that most senior roles in organizations require creativity. But we never just read the article, we always read the paper. And reading this paper, several things got our attention. One is that participants in the study had access to ChatGPT for only one week. We agree with Ethan Mollick that you need about 10 hours with LLMs just to get a feel for how they can benefit you, and one week seems a very short window. Another is that other than “usage examples,” it’s unclear what training, if any, participants had in using LLMs for the type of work they might do. But perhaps most important is the model they used. The paper simply says the model was “ChatGPT.” In August, 2023 (the time of the study) the two versions of ChatGPT available were ChatGPT-3.5 Turbo (certainly) and ChatGPT 4 (possibly, depending on the type of account). While state of the art at the time, both models are now far behind those in use today. How far? This helpful leaderboard benchmark graph (for GPQA, the “Graduate-Level, Google-Proof” benchmark of LLM performance2) shows the gap (those are GPT-3.5 and GPT-4 way over there at the far left):
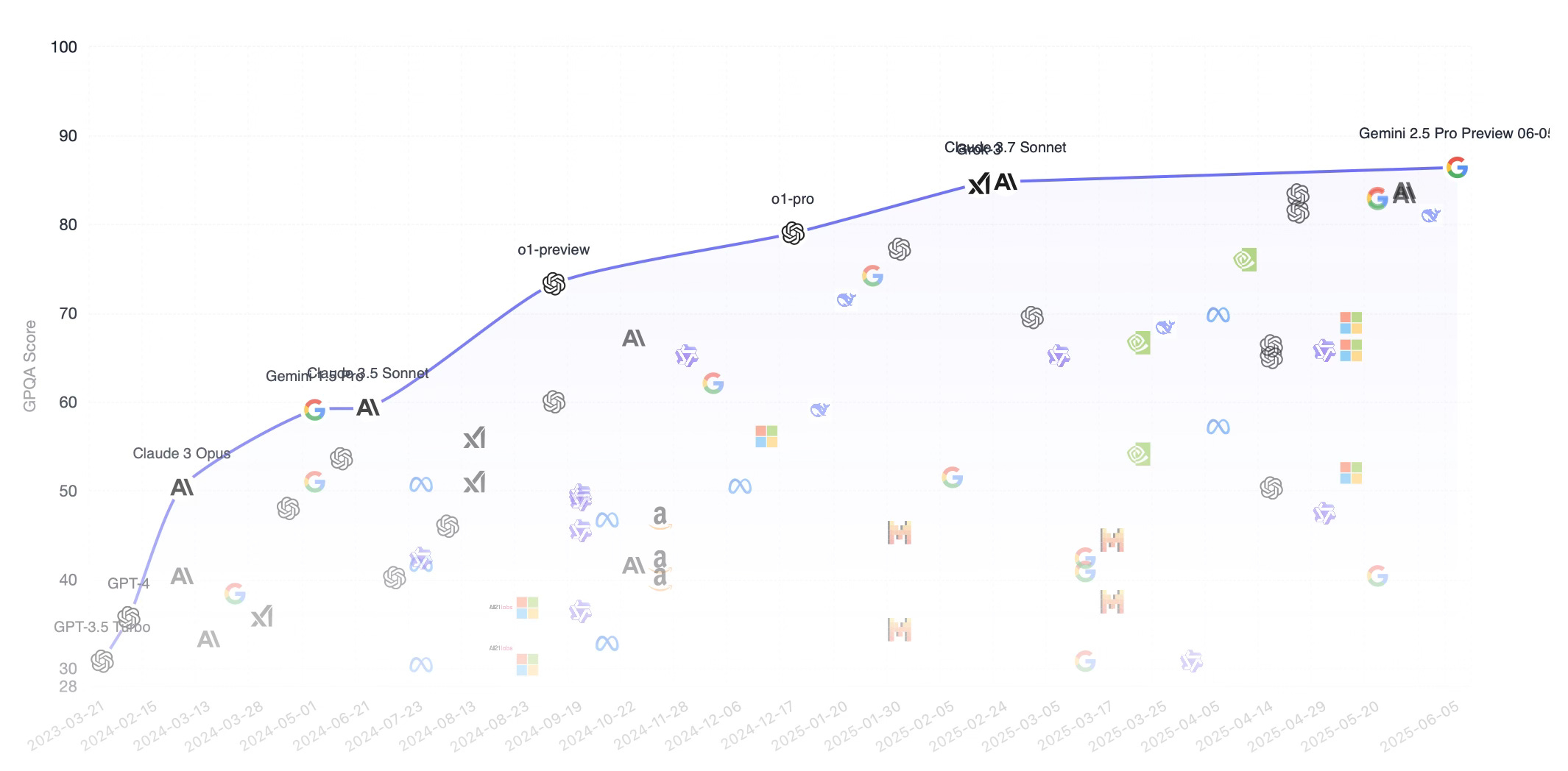
So what should you make of it? Read any news report claiming “LLMs can / can’t” or “LLM’s do / don’t” with caution. If it’s based on research, the methodological details matter, as do the details of the model, user preparation, and more. The person writing the paper probably doesn’t know those nuances, and the time it takes academic research to go from study to publication probably means LLMs have advanced one or more generations since the time of study. What was true then simply may not be true now. It doesn’t mean research using older data can’t provide insight. “Extending ‘GPTs are GPTs’ to Firms” still merits attention because it thoughtfully considers the broad abilities of LLMs and not the specific capabilities of a given model. But we need to mind these details if we are to evaluate the research we read. Always follow the link to the original paper, read the details, and give it to an LLM and ask it some tough questions about the approach. This will help you surface the wheat from the chaff (as will we).
Generative AI Changes Work, but It Also Changes Org Charts
New research shows that when AI handles coordination, traditional management structures shift.
We’ve long understood that generative AI would automate routine tasks. But new research from Harvard Business School holds more nuanced promise: beyond changing what managers and other mid-level employees do, it’s creating opportunities for leaders to reimagine how we structure organizations to foster innovation and employee empowerment.
Harvard Business School professor Manuel Hoffmann’s team studied over 50,000 software developers over two years, tracking how GitHub Copilot (an AI programming tool) changed their work patterns. The findings as reported in the Harvard Business Review were striking: developers using AI shifted 5% more time toward core coding work while time spent on project management activities dropped by 10%. But these shifts weren’t because AI was doing the coding. Instead, coders’ use of AI reduced their need for coordination across the team. Developers worked more autonomously, in smaller groups, and asked for help less frequently.
To understand what this could mean beyond the software development world, we should think about the mechanisms driving this shift. First, generative AI allowed workers to solve problems that previously required manager or peer input. Second, by accelerating routine work, employees had more time for exploration and learning, which traditionally fell outside their scope. There are real efficiency gains, but that’s old news. What’s more interesting here is the proof generative AI can expand what’s possible at every level of an organization.
Who benefits most from this expansion? Hoffmann’s research found that less skilled workers saw greater improvements from AI assistance than their high-performing peers. This democratization of capability will affect talent recruitment and development, and possibly create more diverse pathways to advancement.
To be clear, what these data suggest isn’t so much the total eradication of management layers as their evolution. The study’s authors note that while companies won’t eliminate middle managers entirely, they’ll likely need fewer of them, and those who remain will engage in fundamentally different work. When generative AI handles the coordination that once consumed hours of a manager’s day, they gain time for what only humans do well: building relationships, navigating ambiguity, and driving innovation.
In this new landscape of flatter hierarchies, generative AI enables smaller, more autonomous teams to collaborate effectively. The real test might not be in how well organizations implement AI tools, but in how willing they are to let go of hierarchical structures that no longer serve their purpose. And that’s a human challenge, not a technical one.
We’ll leave you with something cool: Betting platform Kalshi aired a fully AI-generated commercial during the NBA Finals, created for just $2,000 using Google’s new Veo 3 video model.
AI Disclosure: We used generative AI in creating imagery for this post. We also used it selectively as a creator and summarizer of content and as an editor and proofreader.Good afternoon, Claude. We’re going to include a summary of a recent paper in our weekly newsletter on generative AI, Confluence. You can get a flavor for Confluence at http://craai.substack.com. Read a few issues to get the writing style.
Once you have, write a 4-5 paragraph summary of the recent research paper I've attached. The paper is very technical, but make sure your summary is accessible to someone without a deep economics or statistics background. Also, when you write, DO NOT use the “this isn't just X, it's Y” framing which I know you’re tempted to do. Just don't do it.
After summarizing the paper in accessible terms, make some key points about the immediate takeaways. Then, focus on the fact that this paper shows increasing evidence that large language models are general purpose technologies. Remind readers of the characteristics of general purpose technologies, then share some key implications of those characteristics that leaders should be aware of. Avoid overstatement and sensational claims; keep the tone and type of claims consistent with how we’ve written about these things in previous editions of Confluence.
We will list you as the author for this Confluence item, so you get proper credit. Ok ... go, and give it your all!
GPQA is a challenging dataset of 448 multiple-choice questions written by domain experts in biology, physics, and chemistry. The questions are high-quality and extremely difficult: experts who have or are pursuing PhDs in the corresponding domains reach 65% accuracy (74% when discounting clear mistakes the experts identified in retrospect), while highly skilled non-expert validators only reach 34% accuracy, despite spending on average over 30 minutes with unrestricted access to the web (i.e., the questions are "Google-proof"). The questions are also difficult for state-of-the-art AI systems to answer. You may learn more about it here.